When confronted with a need to build a text classifier, the first question to ask is how much training data is there currently available? None? Very little? Quite a lot? Or a huge amount, growing every day? Often one of the biggest practical challenges in fielding a machine learning classifier in real applications is creating or obtaining enough training data. For many problems and algorithms, hundreds or thousands of examples from each class are required to produce a high performance classifier and many real world contexts involve large sets of categories. We will initially assume that the classifier is needed as soon as possible; if a lot of time is available for implementation, much of it might be spent on assembling data resources.
If you have no labeled training data, and especially if there are existing staff knowledgeable about the domain of the data, then you should never forget the solution of using hand-written rules. That is, you write standing queries, as we touched on at the beginning of Chapter 13 . For example:
if (wheat or grain) and not (whole or bread) thenIn practice, rules get a lot bigger than this, and can be phrased using more sophisticated query languages than just Boolean expressions, including the use of numeric scores. With careful crafting (that is, by humans tuning the rules on development data), the accuracy of such rules can become very high. Jacobs and Rau (1990) report identifying articles about takeovers with 92% precision and 88.5% recall, and Hayes and Weinstein (1990) report 94% recall and 84% precision over 675 categories on Reuters newswire documents. Nevertheless the amount of work to create such well-tuned rules is very large. A reasonable estimate is 2 days per class, and extra time has to go into maintenance of rules, as the content of documents in classes drifts over time (cf. page 13.4 ).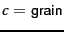
If you have fairly little data and you are going to train a supervised
classifier, then machine learning theory says you should stick to a
classifier with high bias, as we discussed in Section 14.6 (page ![]() ).
For example, there are theoretical and empirical results
that Naive Bayes does well in such circumstances
(Forman and Cohen, 2004, Ng and Jordan, 2001), although this effect is not necessarily
observed in practice with regularized models over textual data
(Klein and Manning, 2002). At any rate, a very low bias model like
a nearest neighbor model is probably counterindicated. Regardless, the
quality of the model will be adversely affected by the limited
training data.
).
For example, there are theoretical and empirical results
that Naive Bayes does well in such circumstances
(Forman and Cohen, 2004, Ng and Jordan, 2001), although this effect is not necessarily
observed in practice with regularized models over textual data
(Klein and Manning, 2002). At any rate, a very low bias model like
a nearest neighbor model is probably counterindicated. Regardless, the
quality of the model will be adversely affected by the limited
training data.
Here, the theoretically interesting answer is to try to
apply semi-supervised training
methods . This includes methods such as bootstrapping or the
EM algorithm, which we will introduce in Section 16.5 (page ![]() ). In
these methods, the system gets some labeled documents, and a
further large supply of unlabeled documents over which it can attempt
to learn. One of the big advantages
of Naive Bayes is that it can be straightforwardly extended to
be a semi-supervised learning algorithm, but for SVMs, there is also
semi-supervised learning work which goes under the title of
transductive SVMs . See the references for pointers.
). In
these methods, the system gets some labeled documents, and a
further large supply of unlabeled documents over which it can attempt
to learn. One of the big advantages
of Naive Bayes is that it can be straightforwardly extended to
be a semi-supervised learning algorithm, but for SVMs, there is also
semi-supervised learning work which goes under the title of
transductive SVMs . See the references for pointers.
Often, the practical answer is to work out how to get more labeled data as quickly as you can. The best way to do this is to insert yourself into a process where humans will be willing to label data for you as part of their natural tasks. For example, in many cases humans will sort or route email for their own purposes, and these actions give information about classes. The alternative of getting human labelers expressly for the task of training classifiers is often difficult to organize, and the labeling is often of lower quality, because the labels are not embedded in a realistic task context. Rather than getting people to label all or a random sample of documents, there has also been considerable research on active learning , where a system is built which decides which documents a human should label. Usually these are the ones on which a classifier is uncertain of the correct classification. This can be effective in reducing annotation costs by a factor of 2-4, but has the problem that the good documents to label to train one type of classifier often are not the good documents to label to train a different type of classifier.
If there is a reasonable amount of labeled data, then you are in the perfect position to use everything that we have presented about text classification. For instance, you may wish to use an SVM. However, if you are deploying a linear classifier such as an SVM, you should probably design an application that overlays a Boolean rule-based classifier over the machine learning classifier. Users frequently like to adjust things that do not come out quite right, and if management gets on the phone and wants the classification of a particular document fixed right now, then this is much easier to do by hand-writing a rule than by working out how to adjust the weights of an SVM without destroying the overall classification accuracy. This is one reason why machine learning models like decision trees which produce user-interpretable Boolean-like models retain considerable popularity.
If a huge amount of data are available, then the choice of classifier probably has little effect on your results and the best choice may be unclear (cf. Banko and Brill, 2001). It may be best to choose a classifier based on the scalability of training or even runtime efficiency. To get to this point, you need to have huge amounts of data. The general rule of thumb is that each doubling of the training data size produces a linear increase in classifier performance, but with very large amounts of data, the improvement becomes sub-linear.