For Reuters-RCV1, we need
![]()
![]() for storing
the dictionary in this scheme.
for storing
the dictionary in this scheme.
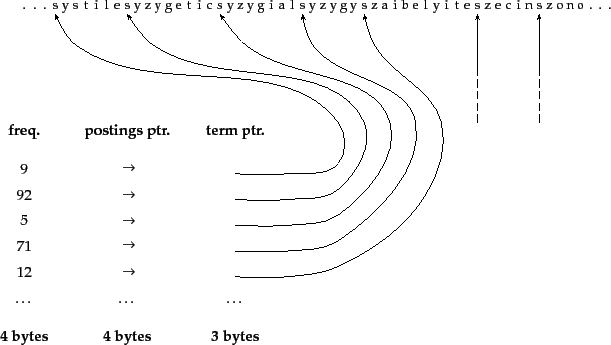 Dictionary-as-a-string storage.Pointers mark
the end of the preceding term and the beginning of the
next. For example, the first three terms in this example
are systile, syzygetic,
and syzygial.
Dictionary-as-a-string storage.Pointers mark
the end of the preceding term and the beginning of the
next. For example, the first three terms in this example
are systile, syzygetic,
and syzygial.
Using fixed-width entries for terms is clearly wasteful. The
average length of a term in English is about eight
characters icompresstb1, so on average we are wasting twelve characters
(or
24 bytes)
in
the fixed-width scheme. Also, we have no way of storing terms with
more than twenty characters like
hydrochlorofluorocarbons
and
supercalifragilisticexpialidocious.
We can
overcome these
shortcomings
by storing the dictionary terms as one long string
of characters, as shown in Figure 5.4 . The
pointer to the next term is also used to demarcate the end
of the current term. As before, we locate terms in the data
structure by way of binary search in the (now smaller) table. This scheme saves us 60%
compared to fixed-width storage -
24 bytes on average of
the 40 bytes
12 bytes on average of
the 20 bytes
we allocated for terms before. However, we now
also need to store term pointers. The term
pointers resolve
![]() positions, so they
need to be
positions, so they
need to be
![]() bits or 3 bytes long.
bits or 3 bytes long.
In this new scheme,
we need
![]() for
the Reuters-RCV1 dictionary:
4 bytes each for frequency and postings
pointer, 3 bytes for the term pointer, and
for
the Reuters-RCV1 dictionary:
4 bytes each for frequency and postings
pointer, 3 bytes for the term pointer, and
![]() bytes on
average for the term.
So we have reduced the space requirements
by one third from 19.211.2 to 10.87.6 MB.
bytes on
average for the term.
So we have reduced the space requirements
by one third from 19.211.2 to 10.87.6 MB.
 Blocked storage with four terms per block.The
first block consists of
systile,
syzygetic,
syzygial, and syzygy with lengths of
seven, nine, eight, and six characters, respectively. Each term is preceded
by a byte encoding its length that
indicates how many bytes
to skip to reach subsequent terms.
Blocked storage with four terms per block.The
first block consists of
systile,
syzygetic,
syzygial, and syzygy with lengths of
seven, nine, eight, and six characters, respectively. Each term is preceded
by a byte encoding its length that
indicates how many bytes
to skip to reach subsequent terms.