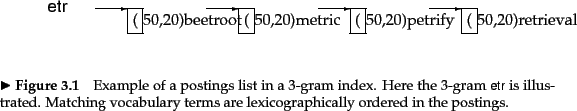Whereas the permuterm index is simple, it can lead to a
considerable blowup from the number of rotations per term; for
a dictionary of English terms, this can represent an almost
ten-fold space increase. We now present a second technique,
known as the ![]() -gram index, for processing wildcard
queries. We will also use
-gram index, for processing wildcard
queries. We will also use ![]() -gram indexes in Section 3.3.4 .
A
-gram indexes in Section 3.3.4 .
A ![]() -gram is a sequence of
-gram is a sequence of ![]() characters. Thus cas, ast and stl are all 3-grams occurring in the term castle. We use a special character $ to denote the beginning or end of a term, so the full set of 3-grams generated for castle is: $ca, cas, ast, stl, tle, le$.
characters. Thus cas, ast and stl are all 3-grams occurring in the term castle. We use a special character $ to denote the beginning or end of a term, so the full set of 3-grams generated for castle is: $ca, cas, ast, stl, tle, le$.
In a ![]() -gram index , the dictionary contains all
-gram index , the dictionary contains all ![]() -grams that occur in any term in the
vocabulary. Each postings list points from a
-grams that occur in any term in the
vocabulary. Each postings list points from a ![]() -gram to all
vocabulary terms containing that
-gram to all
vocabulary terms containing that ![]() -gram. For instance, the
3-gram etr would point to vocabulary terms such as
metric and retrieval. An example is given in
Figure 3.4 .
-gram. For instance, the
3-gram etr would point to vocabulary terms such as
metric and retrieval. An example is given in
Figure 3.4 .
How does such an index help us with wildcard queries? Consider the wildcard query re*ve. We are seeking documents containing any term that begins with re and ends with ve. Accordingly, we run the Boolean query $re AND ve$. This is looked up in the 3-gram index and yields a list of matching terms such as relive, remove and retrieve. Each of these matching terms is then looked up in the standard inverted index to yield documents matching the query.
There is however a difficulty with the use of ![]() -gram indexes, that demands one further step of processing. Consider using the 3-gram index described above for the query red*. Following the process described above, we first issue the Boolean query $re AND red to the 3-gram index. This leads to a match on terms such as retired, which contain the conjunction of the two 3-grams $re and red, yet do not match the original wildcard query red*.
-gram indexes, that demands one further step of processing. Consider using the 3-gram index described above for the query red*. Following the process described above, we first issue the Boolean query $re AND red to the 3-gram index. This leads to a match on terms such as retired, which contain the conjunction of the two 3-grams $re and red, yet do not match the original wildcard query red*.
To cope with this, we introduce a post-filtering step, in which the terms enumerated by the Boolean query on the 3-gram index are checked individually against the original query red*. This is a simple string-matching operation and weeds out terms such as retired that do not match the original query. Terms that survive are then searched in the standard inverted index as usual.
We have seen that a wildcard query can result in multiple terms being enumerated, each of which becomes a single-term query on the standard inverted index. Search engines do allow the combination of wildcard queries using Boolean operators, for example, re*d AND fe*ri. What is the appropriate semantics for such a query? Since each wildcard query turns into a disjunction of single-term queries, the appropriate interpretation of this example is that we have a conjunction of disjunctions: we seek all documents that contain any term matching re*d and any term matching fe*ri.
Even without Boolean combinations of wildcard queries, the processing of a wildcard query can be quite expensive, because of the added lookup in the special index, filtering and finally the standard inverted index. A search engine may support such rich functionality, but most commonly, the capability is hidden behind an interface (say an ``Advanced Query'' interface) that most users never use. Exposing such functionality in the search interface often encourages users to invoke it even when they do not require it (say, by typing a prefix of their query followed by a *), increasing the processing load on the search engine.
Exercises.