




Next: The optimal weight g
Up: Parametric and zone indexes
Previous: Weighted zone scoring
Contents
Index
Learning weights
How do we determine the weights 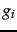 for weighted zone scoring? These weights could be specified by an expert (or, in principle, the user); but increasingly, these weights are ``learned'' using training examples that have been judged editorially. This latter methodology falls under a general class of approaches to scoring and ranking in information retrieval, known as machine-learned relevance . We provide a brief introduction to this topic here because weighted zone scoring presents a clean setting for introducing it; a complete development demands an understanding of machine learning and is deferred to Chapter 15 .
for weighted zone scoring? These weights could be specified by an expert (or, in principle, the user); but increasingly, these weights are ``learned'' using training examples that have been judged editorially. This latter methodology falls under a general class of approaches to scoring and ranking in information retrieval, known as machine-learned relevance . We provide a brief introduction to this topic here because weighted zone scoring presents a clean setting for introducing it; a complete development demands an understanding of machine learning and is deferred to Chapter 15 .
- We are provided with a set of training examples, each of which is a tuple consisting of a query
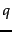 and a document
and a document 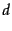 , together with a relevance judgment for on . In the simplest form, each relevance judgments is either Relevant or Non-relevant. More sophisticated implementations of the methodology make use of more nuanced judgments.
, together with a relevance judgment for on . In the simplest form, each relevance judgments is either Relevant or Non-relevant. More sophisticated implementations of the methodology make use of more nuanced judgments.
- The weights are then ``learned'' from these examples, in order that the learned scores approximate the relevance judgments in the training examples.
For weighted zone scoring, the process may be viewed as learning a linear function of the Boolean match scores contributed by the various zones. The expensive component of this methodology is the labor-intensive assembly of user-generated relevance judgments from which to learn the weights, especially in a collection that changes frequently (such as the Web). We now detail a simple example that illustrates how we can reduce the problem of learning the weights to a simple optimization problem.
We now consider a simple case of weighted zone scoring, where each document has a title zone and a body zone. Given a query and a document , we use the given Boolean match function to compute Boolean variables 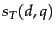 and
and 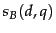 , depending on whether the title (respectively, body) zone of matches query . For instance, the algorithm in Figure 6.4 uses an AND of the query terms for this Boolean function. We will compute a score between 0 and 1 for each (document, query) pair using and by using a constant
, depending on whether the title (respectively, body) zone of matches query . For instance, the algorithm in Figure 6.4 uses an AND of the query terms for this Boolean function. We will compute a score between 0 and 1 for each (document, query) pair using and by using a constant ![$g\in[0,1]$](img372.png) , as follows:
, as follows:
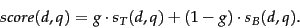 |
(14) |
We now describe how to determine the constant 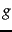 from a set of training examples, each of which is a triple of the form
from a set of training examples, each of which is a triple of the form
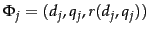 . In each training example, a given training document
. In each training example, a given training document 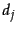 and a given training query
and a given training query 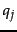 are assessed by a human editor who delivers a relevance judgment
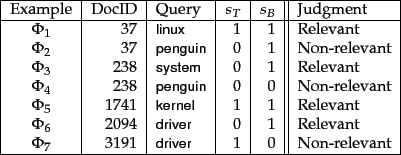
are assessed by a human editor who delivers a relevance judgment 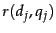 that is either Relevant or Non-relevant. This is illustrated in Figure 6.5 , where seven training examples are shown.
that is either Relevant or Non-relevant. This is illustrated in Figure 6.5 , where seven training examples are shown.
Figure 6.5:
An illustration of training examples.
 |
For each training example 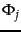 we have Boolean values
we have Boolean values 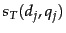 and
and 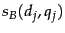 that we use to compute a score from (14)
that we use to compute a score from (14)
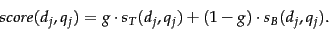 |
(15) |
We now compare this computed score to the human relevance judgment for the same document-query pair 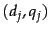 ; to this end, we will quantize each Relevant judgment as a 1 and each Non-relevant judgment as a 0. Suppose that we define the error of the scoring function with weight as
; to this end, we will quantize each Relevant judgment as a 1 and each Non-relevant judgment as a 0. Suppose that we define the error of the scoring function with weight as
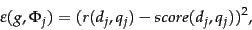 |
(16) |
where we have quantized the editorial relevance judgment to 0 or 1.
Then, the total error of a set of training examples is given by
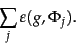 |
(17) |
The problem of learning the constant from the given training examples then reduces to picking the value of that minimizes the total error in (17).
Picking the best value of in (17) in the formulation of Section 6.1.3 reduces to the problem of minimizing a quadratic function of over the interval ![$[0,1]$](img356.png) . This reduction is detailed in Section 6.1.3 .
. This reduction is detailed in Section 6.1.3 .
Next: The optimal weight g
Up: Parametric and zone indexes
Previous: Weighted zone scoring
Contents
Index
© 2008 Cambridge University Press
This is an automatically generated page. In case of formatting errors you may want to look at the PDF edition of the book.
2009-04-07