




Next: References and further reading
Up: Index construction
Previous: Dynamic indexing
Contents
Index
Other types of indexes
This chapter only describes
construction of nonpositional indexes. Except for the much
larger data volume we need to accommodate, the
main
difference for positional indexes is that (termID, docID,
(position1, position2, ...)) triples, instead of (termID,
docID) pairs have to be processed
and that tokens and postings
contain positional information in addition to docIDs. With this
change, the algorithms discussed here can all be applied to
positional indexes.
In the indexes we have
considered so far, postings lists are ordered with respect
to docID. As we
see in Chapter 5, this is advantageous for
compression - instead of docIDs we can compress smaller
gaps between IDs, thus reducing space requirements
for the index. However, this structure for the index is not
optimal when we build ranked (Chapters 6 7 ) - as
opposed to Boolean - retrieval systems . In ranked
retrieval, postings are often ordered according to weight or
impact , with the highest-weighted postings
occurring first. With this organization, scanning of long
postings lists during query processing can usually be
terminated early when weights have become so small that any
further documents can be predicted to be of low similarity
to the query (see Chapter 6 ). In a docID-sorted index,
new documents are always inserted at the end of postings
lists. In an impact-sorted index impactordered, the
insertion can occur anywhere, thus complicating the update of the inverted
index.
Security is an important consideration for retrieval
systems in corporations.
A low-level employee should not be able to find
the salary roster of the
corporation, but authorized managers need to be able to
search for it.
Users' results lists must not contain documents they
are barred from opening; the very existence of a
document can be sensitive information.
Figure:
A user-document matrix for
access control lists. Element 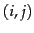 is 1 if user
is 1 if user 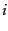 has access to document
has access to document 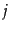 and 0
otherwise. During query processing, a user's access postings list is intersected with
the results list returned by the text part of the index.
and 0
otherwise. During query processing, a user's access postings list is intersected with
the results list returned by the text part of the index.
![\includegraphics[width=10cm]{art/aclmatrix.eps}](img226.png) |
User authorization is often mediated through access
control lists or ACLs. ACLs can be dealt with in an
information retrieval system
by representing each document
as the set
of users that can access them (Figure 4.8 ) and then
inverting the resulting user-document matrix. The inverted
ACL index has, for each user, a ``postings list'' of
documents they can access - the user's access list. Search
results are then intersected with this list. However, such
an index is difficult to maintain when access permissions
change - we discussed these difficulties in the context of
incremental indexing for regular postings lists in
Section 4.5. It also requires the processing of very long postings
lists for users with access to large document subsets. User
membership is therefore often verified by retrieving access
information directly
from the file system at query time -
even though this slows down retrieval.
We discussed
indexes for storing and retrieving terms (as opposed to
documents) in Chapter 3 .
Exercises.
- Can spelling correction compromise document-level
security? Consider the case where a spelling correction is
based on documents to which the user does not have access.
Exercises.
- Total index construction time in
blocked sort-based indexing is broken down in Table 4.3.
Fill out the time column of the table for Reuters-RCV1
assuming a system with the parameters given in Table 4.1 .
Table:
The five steps in constructing an
index for Reuters-RCV1 in blocked sort-based indexing. Line numbers refer to Figure 4.2 .
| | |
Step |
Time |
|
| | 1 |
reading of collection (line 4) |
|
|
| | 2 |
10 initial sorts of 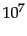 records each (line 5) records each (line 5) |
|
|
| | 3 |
writing of 10 blocks (line 6) |
|
|
| | 4 |
total disk transfer time for merging (line 7) |
|
|
| | 5 |
time of actual merging (line 7) |
|
|
| | |
total |
|
|
- Repeat Exercise 4.6 for the larger
collection in Table 4.4 . Choose a block size
that is realistic for current technology
(remember that a block
should easily fit into main memory).
How many blocks do you need?
- Assume that we have a collection of modest size
whose index can be constructed with the simple in-memory
indexing algorithm
in Figure 1.4 (page
![[*]](http://nlp.stanford.edu/IR-book/html/icons/crossref.png) ). For this collection,
compare memory, disk and time requirements of
the simple algorithm in Figure 1.4 and
blocked sort-based indexing.
). For this collection,
compare memory, disk and time requirements of
the simple algorithm in Figure 1.4 and
blocked sort-based indexing.
-
Assume that machines in MapReduce have 100 GB of disk
space each. Assume further that the postings list of the
term the has a size of 200 GB. Then the MapReduce
algorithm as described cannot be run to construct the index.
How would you modify
MapReduce so that it can handle this case?
- For optimal load
balancing, the inverters in MapReduce must get segmented
postings files of similar sizes. For a new collection, the
distribution of key-value pairs may not be known in
advance. How would you solve this problem?
- Apply MapReduce to the problem of counting how
often each term occurs in a set of files. Specify map and
reduce operations for this task. Write down an example
along the lines of Figure 4.6 .
- We claimed (on page 4.5 ) that an
auxiliary index can impair the quality of collection statistics.
An example is the
term weighting method idf ,
which is defined as
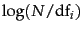 where
where 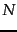 is the total number of documents and
is the total number of documents and 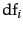 is the
number of documents that term occurs in
idf. Show that
even a small auxiliary index can cause significant error in idf
when it is computed on the main index only. Consider a
rare term that suddenly occurs frequently (e.g.,
Flossie as in Tropical Storm Flossie).
is the
number of documents that term occurs in
idf. Show that
even a small auxiliary index can cause significant error in idf
when it is computed on the main index only. Consider a
rare term that suddenly occurs frequently (e.g.,
Flossie as in Tropical Storm Flossie).
Next: References and further reading
Up: Index construction
Previous: Dynamic indexing
Contents
Index
© 2008 Cambridge University Press
This is an automatically generated page. In case of formatting errors you may want to look at the PDF edition of the book.
2009-04-07