Text Retrieval Conference (TREC) . The U.S.
National
Institute of Standards and Technology (NIST)
has run a large IR test bed evaluation series since 1992. Within this
framework, there have been many tracks over a range of different test
collections, but the best known test collections are the ones used for the
TREC Ad Hoc track during the first 8 TREC evaluations between
1992 and 1999. In total, these test collections comprise 6 CDs containing 1.89 million documents (mainly, but not exclusively, newswire articles) and relevance judgments for
450 information needs, which are called topics
and specified in
detailed text passages. Individual test collections are defined over
different subsets of this data. The early TRECs each consisted of 50
information needs, evaluated over different but overlapping sets of
documents. TRECs 6-8 provide 150 information needs over about 528,000
newswire and Foreign Broadcast Information Service articles.
This is probably the best subcollection to use in future work, because
it is the largest and the topics are more consistent.
Because the test document collections are so
large, there are no exhaustive relevance judgments. Rather, NIST
assessors' relevance judgments are available only for the documents
that were among the top 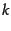 returned for some system which
was entered in the TREC evaluation for which the information need was
developed.
returned for some system which
was entered in the TREC evaluation for which the information need was
developed.
In more recent years, NIST has done evaluations on larger document
collections, including the 25 million page GOV2 web page collection.
From the beginning, the NIST test document collections were orders of magnitude
larger than anything available to researchers previously and GOV2 is
now the largest Web collection easily available for research purposes.
Nevertheless, the size of GOV2 is still more than 2 orders of magnitude
smaller than the current size of the document collections indexed by
the large web search companies.