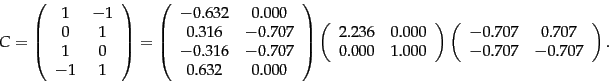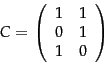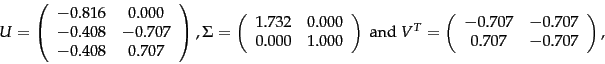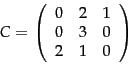Theorem.
Let ![]() be the rank of the
be the rank of the
![]() matrix
matrix ![]() . Then, there is a singular-value decomposition ( SVD for short) of
. Then, there is a singular-value decomposition ( SVD for short) of ![]() of the form
of the form
The values ![]() are referred to as the singular values of
are referred to as the singular values of ![]() . It is instructive to examine the relationship of Theorem 18.2 to Theorem 18.1.1; we do this rather than derive the general proof of Theorem 18.2, which is beyond the scope of this book.
. It is instructive to examine the relationship of Theorem 18.2 to Theorem 18.1.1; we do this rather than derive the general proof of Theorem 18.2, which is beyond the scope of this book.
By multiplying Equation 232 by its transposed version, we have
Note now that in Equation 233, the left-hand side is a square symmetric matrix real-valued matrix, and the right-hand side represents its symmetric diagonal decomposition as in Theorem 18.1.1. What does the left-hand side
![]() represent? It is a square matrix with a row and a column corresponding to each of the
represent? It is a square matrix with a row and a column corresponding to each of the ![]() terms. The entry
terms. The entry ![]() in the matrix is a measure of the overlap between the
in the matrix is a measure of the overlap between the ![]() th and
th and ![]() th terms, based on their co-occurrence in documents. The precise mathematical meaning depends on the manner in which
th terms, based on their co-occurrence in documents. The precise mathematical meaning depends on the manner in which ![]() is constructed based on term weighting. Consider the case where
is constructed based on term weighting. Consider the case where ![]() is the term-document incidence matrix of page 1.1 , illustrated in Figure 1.1 . Then the entry
is the term-document incidence matrix of page 1.1 , illustrated in Figure 1.1 . Then the entry ![]() in
in
![]() is the number of documents in which both term
is the number of documents in which both term ![]() and term
and term ![]() occur.
occur.

When writing down the numerical values of the SVD, it is conventional to represent ![]() as an
as an ![]() matrix with the singular values on the diagonals, since all its entries outside this sub-matrix are zeros. Accordingly, it is conventional to omit the rightmost
matrix with the singular values on the diagonals, since all its entries outside this sub-matrix are zeros. Accordingly, it is conventional to omit the rightmost ![]() columns of
columns of ![]() corresponding to these omitted rows of
corresponding to these omitted rows of ![]() ; likewise the rightmost
; likewise the rightmost ![]() columns of
columns of ![]() are omitted since they correspond in
are omitted since they correspond in ![]() to the rows that will be multiplied by the
to the rows that will be multiplied by the ![]() columns of zeros in
columns of zeros in ![]() . This written form of the SVD is sometimes known as the reduced SVD or truncated SVD and we will encounter it again in Exercise 18.3 . Henceforth, our numerical examples and exercises will use this reduced form.
. This written form of the SVD is sometimes known as the reduced SVD or truncated SVD and we will encounter it again in Exercise 18.3 . Henceforth, our numerical examples and exercises will use this reduced form.
Worked example.
We now illustrate the singular-value decomposition of a ![]() matrix of rank 2; the singular values are
matrix of rank 2; the singular values are
![]() and
and ![]() .
.
End worked example.
As with the matrix decompositions defined in Section 18.1.1 , the singular value decomposition of a matrix can be computed by a variety of algorithms, many of which have been publicly available software implementations; pointers to these are given in Section 18.5 .
Exercises.