WikiTableQuestions: a Complex Real-World Question Understanding Dataset
Ice Pasupat 02/11/2016

Natural language question understanding has been one of the most important challenges in artificial intelligence. Indeed, eminent AI benchmarks such as the Turing test require an AI system to understand natural language questions, with various topics and complexity, and then respond appropriately. During the past few years, we have witnessed rapid progress in question answering technology, with virtual assistants like Siri, Google Now, and Cortana answering daily life questions, and IBM Watson winning over humans in Jeopardy!. However, even the best question answering systems today still face two main challenges that have to solved simultaneously:
-
Question complexity (depth). Many questions the systems encounter are simple lookup questions (e.g., "Where is Chichen Itza?" or "Who's the manager of Man Utd?"). The answers can be found by searching the surface forms. But occasionally users will want to ask questions that require multiple, non-trivial steps to answer (e.g., "What the cheapest bus to Chichen Itza leaving tomorrow?" or "How many times did Manchester United reach the final round of Premier League while Ferguson was the manager?"). These questions require deeper understanding and cannot be answered just by retrieval.
-
Domain size (breadth). Many systems are trained or engineered to work very well in a few specific domains such as managing calendar schedules or finding restaurants. Developing a system to handle questions in any topic from local weather to global military conflicts, however, is much more difficult.
While most systems understand questions containing either depth or breadth alone (e.g., by handling complex questions in a few domains and fall back to web search on the rest), they often struggle on ones that require both. To this end, we have decided to create a new dataset, WikiTableQuestions, that address both challenges at the same time.
Task and Dataset
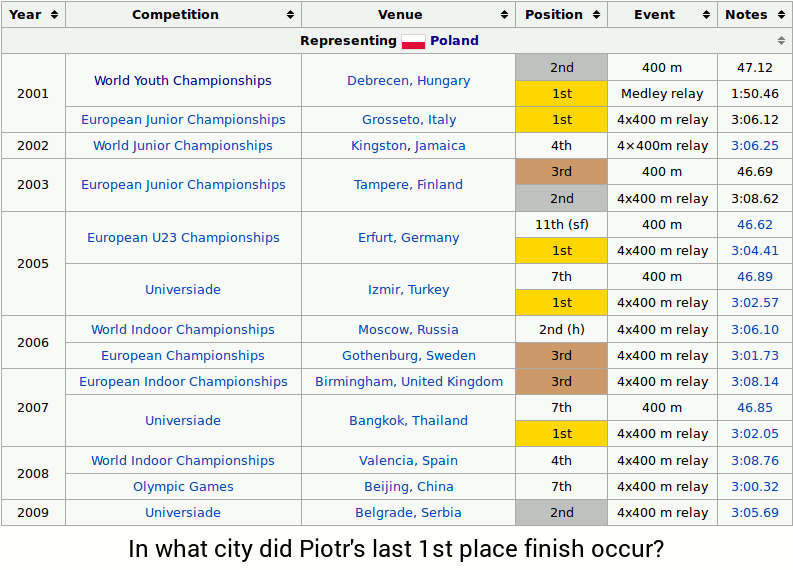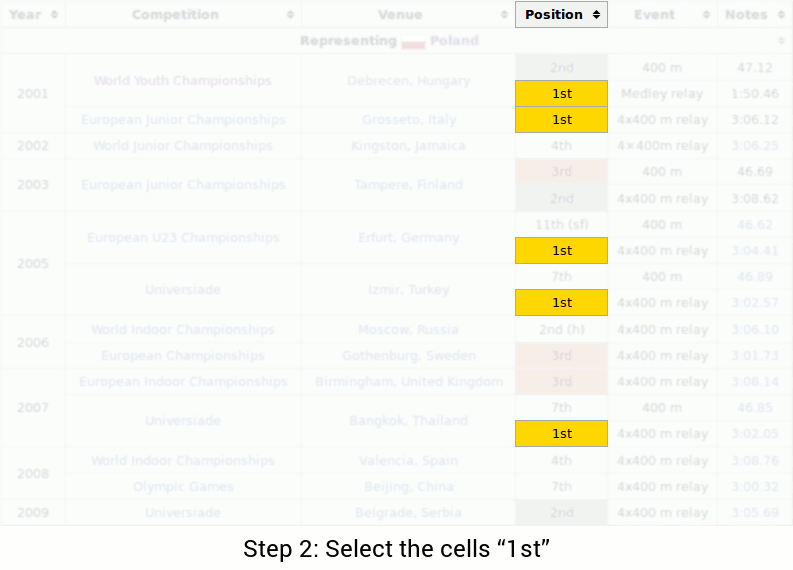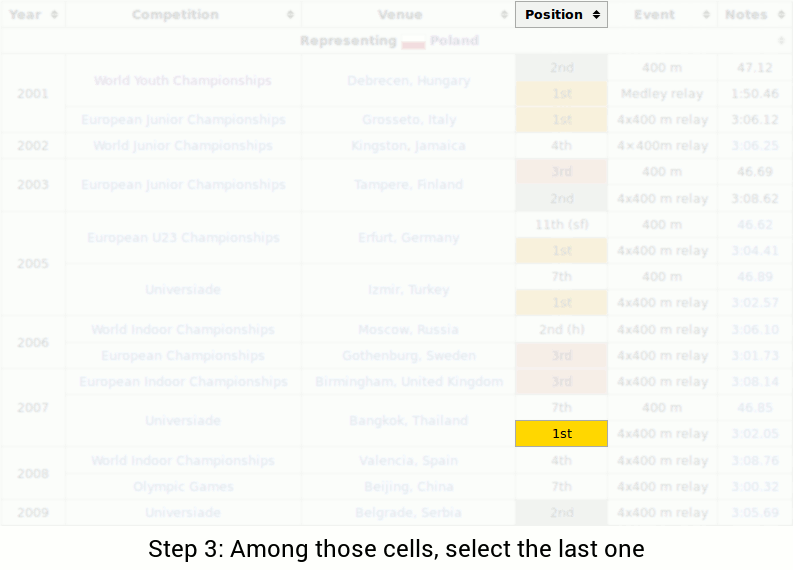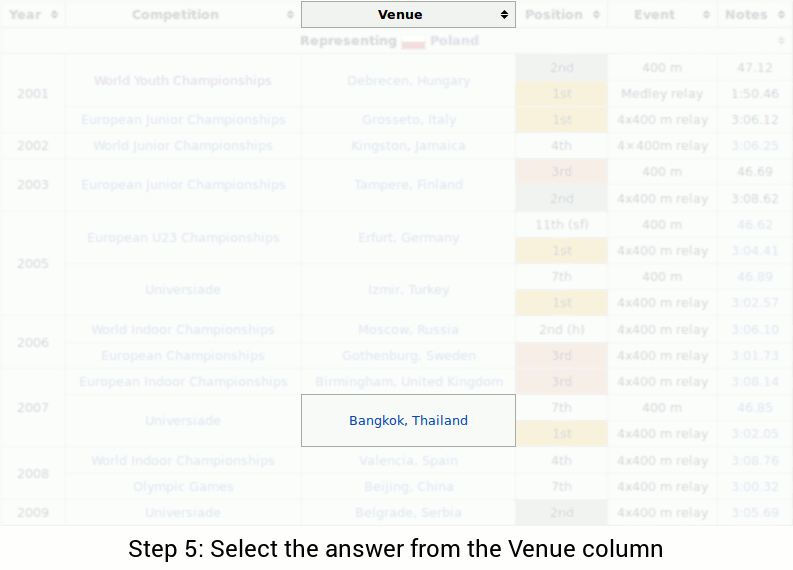
In the WikiTableQuestions dataset, each question comes with a table from Wikipedia. Given the question and the table, the task is to answer the question based on the table. The dataset contains 2108 tables from a large variety of topics (more breadth) and 22033 questions with different complexity (more depth). Tables in the test set do not appear in the training set, so a system must be able to generalize to unseen tables.
The dataset can be accessed from the project page or on CodaLab. The training set can also be browsed online.
We now give some examples that demonstrate the challenges of the dataset. Consider the following table:
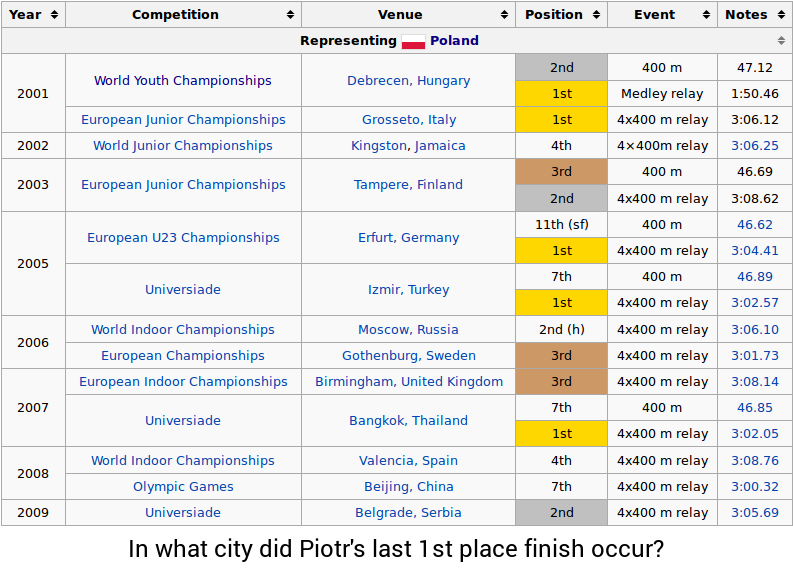
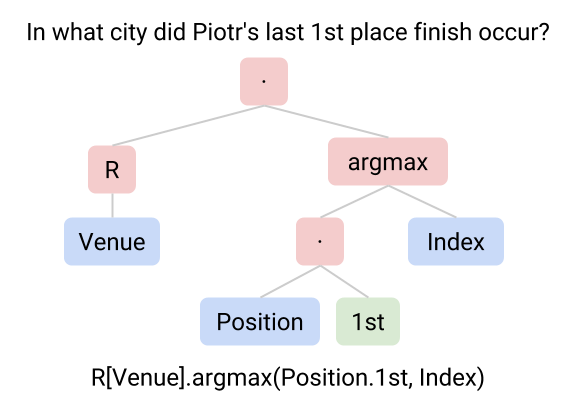
The question is "In what city did Piotr's last 1st place finish occur?" In order to answer the question, one might perform the following steps:
With this example, we can observe several challenges:
-
Schema mapping. One fundamental challenge when working with messy real-world data is handling diverse and possibly unseen data schemas. In this case, the system must know that the word "place" refers to the "Position" column while the word "city" refers to the "Venue" column, even if the same table schema has not been observed before during training.
-
Compositionality. Natural language can express complex ideas thanks to the principle of compositionality: the ability to compose smaller phrases into bigger ones. Small phrases could correspond to different operations (e.g., locating the last item), which can be composed to get the final answer.
-
Variety of operations. To fully utilize a rich data source, it is essential to be able to perform different operations such as filtering data ("1st place", "in 1990"), pinpointing data ("the longest", "the first"), computing statistics ("total", "average", "how many"), and comparing quantities ("difference between", "at least 10"). The WikiTableQuestions dataset contains questions with a large variety of operations, some of which can be observed in other questions for the table above:
- what was piotr's total number of 3rd place finishes?
- which competition did this competitor compete in next after the world indoor championships in 2008?
- how long did it take piotr to run the medley relay in 2001?
- which 4x400 was faster, 2005 or 2003?
- how many times has this competitor placed 5th or better in competition?
- Common sense reasoning. Finally, one of the most challenging aspect of natural language is that the meaning of some phrases must be inferred using the context and common sense. For instance, the word "better" in the last example (... placed 5th or better …) means "Position ≤ 5", but in "scored 5 or better" it means "Score ≥ 5".
Here are some other examples (cherry-picked from the first 50 examples) that show the variety of operations and topics of our dataset:
- how many people stayed at least 3 years in office?
- which players played the same position as ardo kreek?
- in how many games did the winning team score more than 4 points?
- what's the number of parishes founded in the 1800s?
- in 1996 the sc house of representatives had a republican majority. how many years had passed since the last time this happened?
- how many consecutive friendly competitions did chalupny score in?
Comparison to Existing QA Datasets
Most QA datasets address only either breadth (domain size) or depth (question complexity). Early semantic parsing datasets such as GeoQuery and ATIS contain complex sentences (high depth) in a focused domain (low breadth). Here are some examples from GeoQuery, which contains questions on a US geography database:
- how many states border texas?
- what states border texas and have a major river?
- what is the total population of the states that border texas?
- what states border states that border states that border states that border texas?
More recently, Facebook released the bAbI dataset featuring 20 types of automatically generated questions with different complexity on simulated worlds. Here is an example:
John picked up the apple.
John went to the office.
John went to the kitchen.
John dropped the apple.
Question: Where was the apple before the kitchen?
In contrast, many QA datasets contain questions spanning a variety of topics (high breadth), but the questions are much simpler or retrieval-based (low depth). For example, WebQuestions dataset contains factoid questions that can be answered using a structured knowledge base. Here are some examples:
- what is the name of justin bieber brother?
- what character did natalie portman play in star wars?
- where donald trump went to college?
- what countries around the world speak french?
Other knowledge base QA datasets include Free917 (also on Freebase) and QALD (on both knowledge bases and unstructured data).
QA datasets that focus on information retrieval and answer selection (such as TREC, WikiQA, QANTA Quiz Bowl, and many Jeopardy! questions) are also of this kind: while some questions in these datasets look complex, the answers can be mostly inferred by working with the surface form. Here is an example from QANTA Quiz Bowl dataset:
With the assistence of his chief minister, the Duc de Sully, he lowered taxes on peasantry, promoted economic recovery, and instituted a tax on the Paulette. Victor at Ivry and Arquet, he was excluded from succession by the Treaty of Nemours, but won a great victory at Coutras. His excommunication was lifted by Clement VIII, but that pope later claimed to be crucified when this monarch promulgated the Edict of Nantes. For 10 points, name this French king, the first Bourbon who admitted that "Paris is worth a mass" when he converted following the War of the Three Henrys.
Finally, there are several datasets that address both breadth and depth but in a different angle. For example, QALD Hybrid QA requires the system to combine information from multiple data sources, and in AI2 Science Exam Questions and Todai Robot University Entrance Questions, the system has to perform common sense reasoning and logical inference on a large volume of knowledge to derive the answers.
State of the Art on WikiTableQuestions Dataset
In our paper, we present a semantic parsing system which learns to construct formal queries ("logical forms") that can be executed on the tables to get the answers.
The system learns a statistical model that builds logical forms in a hierarchical fashion (more depth) using parts can be freely constructed from any table schema (more breadth). The system achieve a test accuracy of 37.1%, which is higher than the previous semantic parsing system and an information retrieval baseline.
We encourage everyone to play with the dataset, develop systems to tackle the challenges, and advance the field of natural language understanding! For suggestions and comments on the dataset, please contact the author Ice Pasupat.