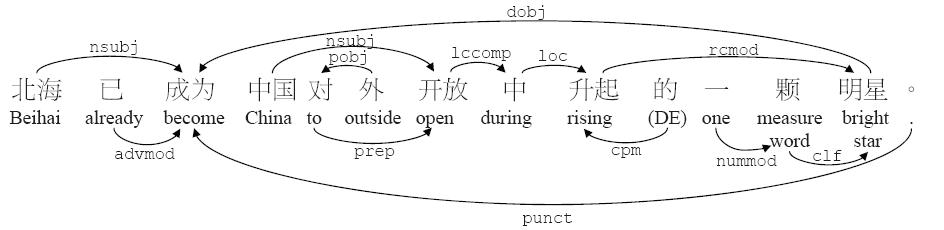
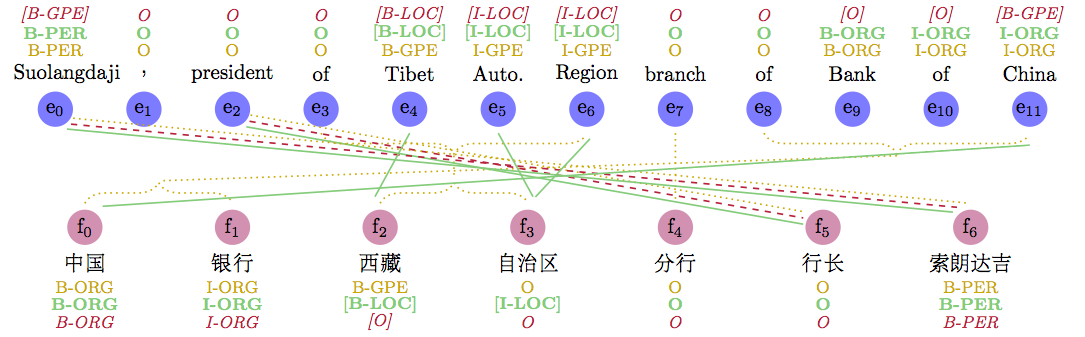
We work on a wide variety of research in Chinese Natural Language
Processing and speech processing, including word segmentation,
part-of-speech tagging, syntactic and semantic parsing, machine
translation, disfluency detection, prosody, and other areas. We
provide softwares for Chinese word segmentation, Chinese parsing and
Chinese part-of-speech tagging.
More details on each topic:
Speech Processing
Our Chinese speech research has focused on areas like the study and detection of
disfluencies (filled pauses like uh and word fragments), prosody, and the detection
of speech acts.
People
Software
Publications
Cross-lingual Pseudo-Projected Expectation Regularization for Weakly Supervised Learning
[pdf]
Mengqiu Wang and Christopher D. Manning.
in Transactions of ACL, 2013.
Joint Word Alignment and Bilingual Named Entity Recognition Using Dual Decomposition
[pdf]
Mengqiu Wang, Wanxiang Che and Christopher D. Manning.
in Proceedings of ACL, 2013.
Effective Bilingual Constraints for Semi-supervised Learning of Named Entity Recognizers
[pdf]
Mengqiu Wang, Wanxiang Che and Christopher D. Manning.
in Proceedings of AAAI, 2013.
Named Entity Recognition with Bilingual Constraints
[pdf]
Wanxiang Che, Mengqiu Wang and Christopher D. Manning.
in Proceedings of NAACL, 2013.
Discriminative Reordering with Chinese Grammatical Relations Features
[pdf]
Pi-Chuan Chang, Huihsin Tseng, Dan Jurafsky, and Christopher D. Manning.
in NAACL 2009 Third Workshop on Syntax and Structure in Statistical Translation.
Disambiguating "DE" for Chinese-English Machine Translation
[pdf]
Pi-Chuan Chang, Dan Jurafsky and Christopher D. Manning.
in EACL 2009 Fourth Workshop on Statistical Machine Translation.
Optimizing Chinese Word Segmentation for Machine Translation Performance
[pdf]
Pi-Chuan Chang, Michel Galley and Christopher D. Manning.
in ACL 2008 Third Workshop on Statistical Machine Translation.
Stanford University's Chinese-to-English Statistical Machine Translation System for the 2008 NIST Evaluation
[pdf]
Michel Galley, Pi-Chuan Chang, Daniel Cer, Jenny R. Finkel, Christopher D. Manning.
in Proceedings of the 2008 NIST Open Machine Translation Evaluation Workshop.
Detection of Word Fragments in Mandarin Telephone Conversation
[pdf]
Cheng-Tao Chu, Yun-Hsuan Sung, Yuan Zhao, Dan Jurafsky.
Proceedings of INTERSPEECH-2006, Pittsburgh, PA.
A Conditional Random Field Word Segmenter for SIGHAN Bakeoff 2005
[pdf]
Huihsin Tseng, Pichuan Chang, Galen Andrew, Daniel Jurafsky, and Christopher Manning
The Fourth SIGHAN Workshop on Chinese Language Processing, 2005
Morphological features help POS tagging of unknown words across language varieties
[pdf]
Huihsin Tseng, Daniel Jurafsky, Christopher Manning
The Fourth SIGHAN Workshop on Chinese Language Processing, 2005
Accent Detection and Speech Recognition for Shanghai-Accented Mandarin
[pdf]
Yanli Zheng, Richard Sproat, Liang Gu, Izhak Shafran, Haolang Zhou,
Yi Su, Dan Jurafsky, Rebecca Starr and Su-Youn Yoon.
Proceedings of EUROSPEECH-05
A preliminary study of Mandarin filled pauses
[pdf]
Yuan Zhao and Dan Jurafsky
Proceedings of DiSS'05, Disfluency in Spontaneous Speech Workshop
Detection of Questions in Chinese Conversation
[pdf]
Yuan, Jiahong and Dan Jurafsky
Proceedings of IEEE ASRU 2005
Parsing Arguments of Nominalizations in English and Chinese
[pdf
]
Pradhan, Sameer, Honglin Sun, Wayne Ward, James H. Martin, and
Daniel Jurafsky
Proceedings of NAACL-HLT 2004.
Is it harder to parse Chinese, or the Chinese Treebank?
[pdf]
Roger Levy and Christopher Manning
Proceedings of ACL 2003
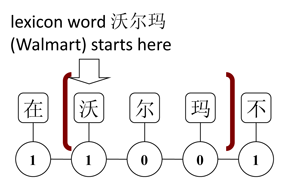 Our Chinese word segmenter relies on a linear-chain conditional random
filed (CRF) model, which treats word segmentation as a binary decision
task. It uses three categories of features: character identity
n-grams, morphological and character reduplication features. As shown
in the figure on the right, it also exploits lexicons and proper noun
features to improve segmentation consistency, which is beneficial in
tasks such as machine translation (MT) and information retrieval. In
(Chang et al., 2008), we show that this increase of consistency yields
an improvement of 0.32 BLEU point on a standard test set, and an
additional improvement of 0.73 BLEU when segmentation granularity is
optimized for the MT task.
Our Chinese word segmenter relies on a linear-chain conditional random
filed (CRF) model, which treats word segmentation as a binary decision
task. It uses three categories of features: character identity
n-grams, morphological and character reduplication features. As shown
in the figure on the right, it also exploits lexicons and proper noun
features to improve segmentation consistency, which is beneficial in
tasks such as machine translation (MT) and information retrieval. In
(Chang et al., 2008), we show that this increase of consistency yields
an improvement of 0.32 BLEU point on a standard test set, and an
additional improvement of 0.73 BLEU when segmentation granularity is
optimized for the MT task.