HistWords is a collection of tools and datasets for analyzing language change using word vector embeddings.
The goal of this project is to facilitate quantitative research in diachronic linguistics, history, and the digital humanities.
We used the historical word vectors in HistWords to study the semantic evolution of more than 30,000 words across 4 languages.
This study led us to propose two statistical laws that govern the evolution of word meaning (paper link).
Law of conformity: words that are used more frequently change less and have meanings that are more stable over time.
Law of innovation: words that are polysemous (have many meanings) change at faster rates.
We released pre-trained historical word embeddings (spanning all decades from 1800 to 2000) for multiple languages (English, French, German, and Chinese).
Embeddings constructed from many different corpora and using different embedding approaches are included.
The paper Diachronic Word Embeddings Reveal Statistical Laws of Semantic Change details how these embeddings were constructed.
Getting started (Code download)
All the code is available
on GitHub
Download pre-trained word vectors
1. Historical Word2Vec (SGNS) embeddings (get started quick)
These downloads contain historical word2vec vectors without any extra stats or other information.
The the HistWords code contains tools (and examples) for manipulating the embeddings.
2. Multiple historical embedding types + detailed historical statistics
These downloads contain all the data necessary to replicate the results of our published study, using the three types of embeddings described in that work.
Each corpus zip-file includes these historical, post-processed word vectors along with some useful historical statistics.
See this page for a detailed description of the data.
This data is available for all the corpora:
This data is made available under the
Public Domain Dedication
and License v1.0 whose full text can be found at:
http://www.opendatacommons.org/licenses/pddl/1.0/.
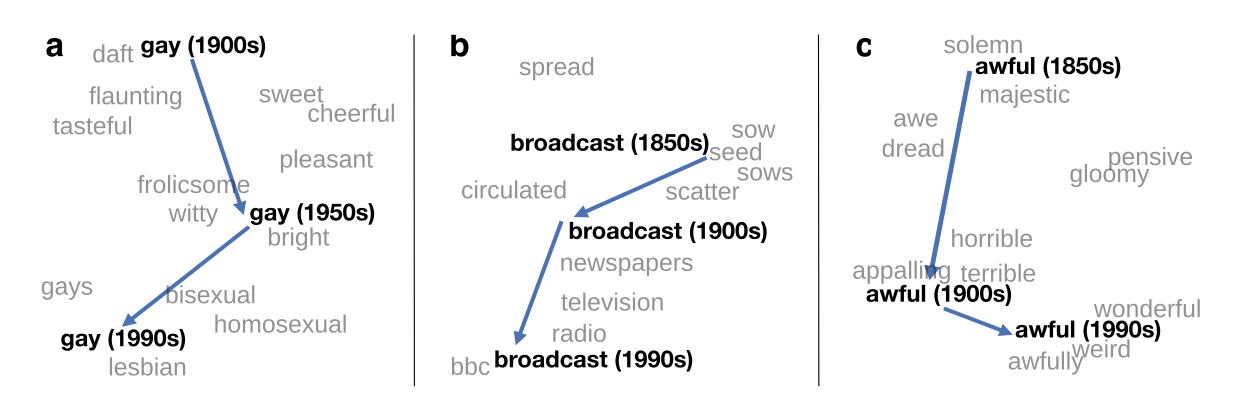
1. Visualizing changes in word meaning
Changes in word meaning can be visualized by projecting historical word vectors into a 2-D space.
- Gay shifted in meaning over the last century, from meaning "showy" or "cheerful" to denoting "homosexuality".
- Broadcast used to refer to the act of throwing seeds, but then this motion became associated with the throwing of newspapers, and eventually broadcast developed its current meaning of "disseminating information."
- Awful underwent a process known as pejoration; it used to literally mean "full of awe", but over time it became more negative and now signifies that something is "upsetting."
2. Uncovering statistical laws of semantic change
Using historical word embeddings we measured the rate of semantic change for thousands of words across 7 datasets, 4 languages, and 150 years.
These quantitative measurements allowed us to propose new statistical laws of semantic change.
We found that
- The meanings of higher-frequency (i.e., more common) words are more stable. This means that words that get used a lot tend to keep the meanings, while uncommon words can gain new meanings more easily.
- Words that are more polysemous (i.e., that have more meanings, or are used in more contexts) tend to change faster. This means that words that can be used in lots of different ways (like the word "like") tend to be more semantically unstable.
GitHub: HistWords is on
GitHub. For bug reports and patches, you're best off using the
GitHub Issues and Pull requests features.