Software > Stanford OpenIE
Stanford Open Information Extraction
| About | Download | Usage | Support | Questions | Release history |
About
Open information extraction (open IE) refers to the extraction of relation tuples, typically binary relations, from plain text, such as (Mark Zuckerberg; founded; Facebook). The central difference from other information extraction is that the schema for these relations does not need to be specified in advance; typically the relation name is just the text linking two arguments. For example, Barack Obama was born in Hawaii would create a triple (Barack Obama; was born in; Hawaii), corresponding to the open domain relation was-born-in(Barack-Obama, Hawaii). This software is a Java implementation of an open IE system described in the paper:
Gabor Angeli, Melvin Johnson Premkumar, and Christopher D. Manning. Leveraging Linguistic Structure For Open Domain Information Extraction. In Proceedings of the Association of Computational Linguistics (ACL), 2015.
The system first splits each sentence into a set of entailed clauses. Each clause is then maximally shortened, producing a set of entailed shorter sentence fragments. These fragments are then segmented into OpenIE triples, and output by the system. An illustration of the process is given for an example sentence below:
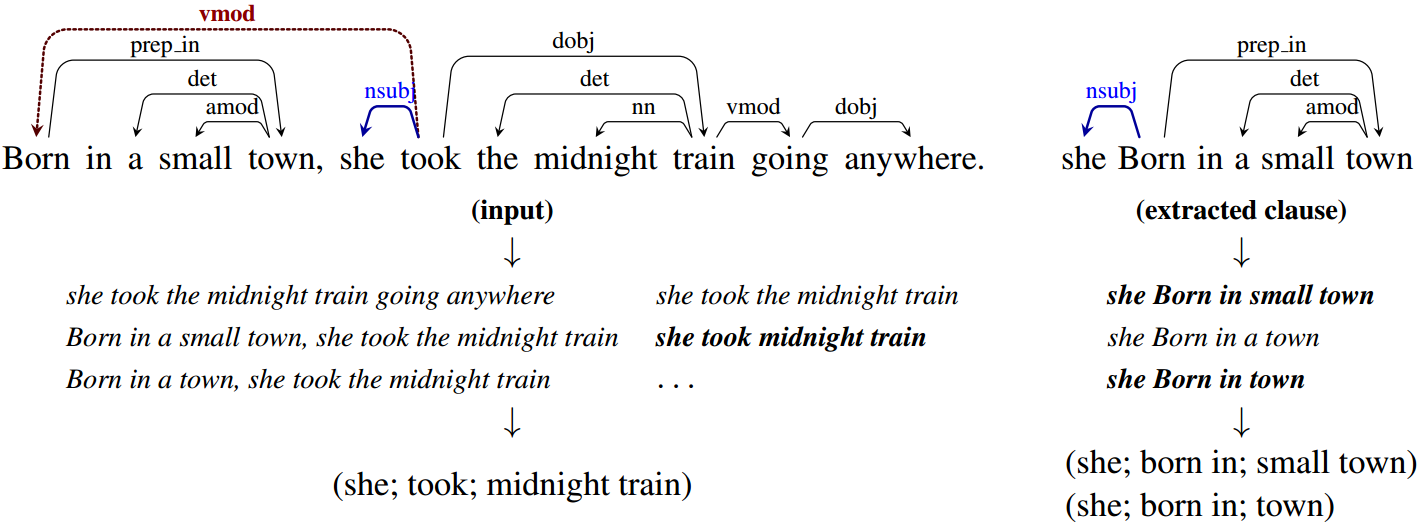
The system was originally written by Gabor Angeli and Melvin Johnson Premkumar.
It requires Java 8+ to be installed, and generally requires around
50MB of memory in addition to the memory used by the part of speech tagger and
dependency parser (and optional named entity recognizer).
We recommend running java with around 1gb of memory (2gb if using NER) to be safe
(i.e., java -mx1g).
The system is licensed under the GNU General Public License (v2 or later). Source is included. The code includes components for command-line invocation and a Java API. The code is dual licensed (in a similar manner to MySQL, etc.). Open source licensing is under the full GPL, which allows many free uses. For distributors of proprietary software, commercial licensing is available. If you don't need a commercial license, but would like to support maintenance of these tools, we welcome gift funding.
Download
Stanford OpenIE is a part of Stanford CoreNLP. Download a copy of CoreNLP, and you are ready to go!
Usage
Once downloaded, the code can be invoked either programmatically or from the command line, either directly via its own class or through running StanfordCoreNLP with the openie annotator. The OpenIE program provides some useful OpenIE triple output formats and can be invoked with the following command. This will read lines from standard input, and produce relation triples in a tab separated format: (confidence; subject; relation; object).
java -mx1g -cp "*" edu.stanford.nlp.naturalli.OpenIE
To process files, simply pass them in as arguments to the program. For example,
java -mx1g -cp "*" edu.stanford.nlp.naturalli.OpenIE /path/to/file1 /path/to/file2
In addition, there are a number of flags you can set to tweak the behavior of the program.
| -format | {reverb, ollie, default} | Change the output format of the program. Default will produce tab separated columns for confidence, the subject, relation, and the object of a relation. ReVerb will output a TSV in the ReVerb format. Ollie will output relations in the default format returned by Ollie. |
| -filelist | /path/to/filelist | A path to a file, which contains files to annotate. Each file should be on its own line. If this option is set, only these files are annotated and the files passed via bare arguments are ignored. |
| -threads | integer | The number of threads to run on. By default, this is the number of threads on the system. |
| -max_entailments_per_clause | integer | The maximum number of entailments to produce for each clause extracted in the sentence. The larger this value is, the slower the system will run, but the more relations it can potentially extract. Setting this below 100 is not recommended; setting it above 1000 is likewise not recommended. |
| -resolve_coref | boolean | If true, resolve pronouns to their canonical antecedent. This option requires additional CoreNLP annotators not included in the distribution, and therefore only works if used with the CoreNLP OpenIE annotator, or invoked via the command line from the CoreNLP jar. |
| -ignore_affinity | boolean | Ignore the affinity model for prepositional attachments. |
| -affinity_probability_cap | double | The affinity value above which confidence of the extraction is taken as 1.0. Default is 1/3. |
| -triple.strict | boolean | If true (the default), extract triples only if they consume the entire fragment. This is useful for ensuring that only logically warranted triples are extracted, but puts more burden on the entailment system to find minimal phrases (see -max_entailments_per_clause). |
| -triple.all_nominals | boolean | If true, extract nominal relations always and not only when a named entity tag warrants it. This greatly overproduces such triples, but can be useful in certain situations. |
| -splitter.model | /path/to/model.ser.gz | [rare] You can override the default location of the clause splitting model with this option. |
| -splitter.nomodel | [rare] Run without a clause splitting model -- that is, split on every clause. | |
| -splitter.disable | [rare] Don't split clauses at all, and only extract relations centered around the root verb. | |
| -affinity_model | /path/to/model_dir | [rare] A custom location to read the affinity models from. |
The code can also be invoked programatically, using
Stanford CoreNLP.
For this, simply include the annotators natlog and openie in the annotators property,
and add any of the flags described above to the properties file prepended
with the string "openie.", e.g., "openie.format = ollie".
Note that openie depends on the annotators "tokenize,ssplit,pos,depparse".
We include example working code in the file OpenIEDemo.java.
This demo class will annotate the text "Obama was born in Hawaii. He is our president,"
and print out each extraction from the document to the console.
Frequently Asked Questions
See Support.
Support
We recommend asking questions on StackOverflow, using the
stanford-nlp tag.
In addition, we have 3 mailing lists that you can write to,
all of which are shared
with other JavaNLP tools (with the exclusion of the parser). Each address is
at @lists.stanford.edu:
java-nlp-userThis is the best list to post to in order to send feature requests, make announcements, or for discussion among JavaNLP users. (Please ask support questions on Stack Overflow using the stanford-nlp tag.)You have to subscribe to be able to use this list. Join the list via this webpage or by emailing
java-nlp-user-join@lists.stanford.edu. (Leave the subject and message body empty.) You can also look at the list archives.java-nlp-announceThis list will be used only to announce new versions of Stanford JavaNLP tools. So it will be very low volume (expect 1-3 messages a year). Join the list via this webpage or by emailingjava-nlp-announce-join@lists.stanford.edu. (Leave the subject and message body empty.)java-nlp-supportThis list goes only to the software maintainers. It's a good address for licensing questions, etc. For general use and support questions, you're better off joining and usingjava-nlp-user. You cannot joinjava-nlp-support, but you can mail questions tojava-nlp-support@lists.stanford.edu.
Release History
| Version | Date | Description | Resources |
|---|---|---|---|
| 3.6.0 | 2015-12-09 | First release | code / models / source |
~~~ Outdated instructions ~~~
Below are the original download instructions. They are now outdated. Since the release of CoreNLP v. 3.6.0, you should get the latest version by downloading CoreNLP!
To run the code, you need both the OpenIE code jar, as well as the models jar in your classpath. Both of these must be included for the system to work. These can be downloaded below:
| Download the original OpenIE Code [5.5 MB] |
| Download the original OpenIE Models [58 MB] |
The source code for the system can be downloaded from the link below:
Lastly, if you have already downloaded models for the dependency parser and part-of-speech tagger, you can download only the OpenIE models from the link below. This is not recommended unless you are sure you know what you are doing.