Software > SPIED
Stanford Pattern-based Information Extraction and Diagnostics (SPIED)
Pattern-based entity extraction and visualization
This software provides code for two components:
- Learning entities from unlabeled text starting with seed sets using patterns in an iterative fashion
- Visualizing and diagnosing the output from one to two systems.
Bootstrapped Entity Learning
About | Downloads | Usage | FAQ | Release history
About
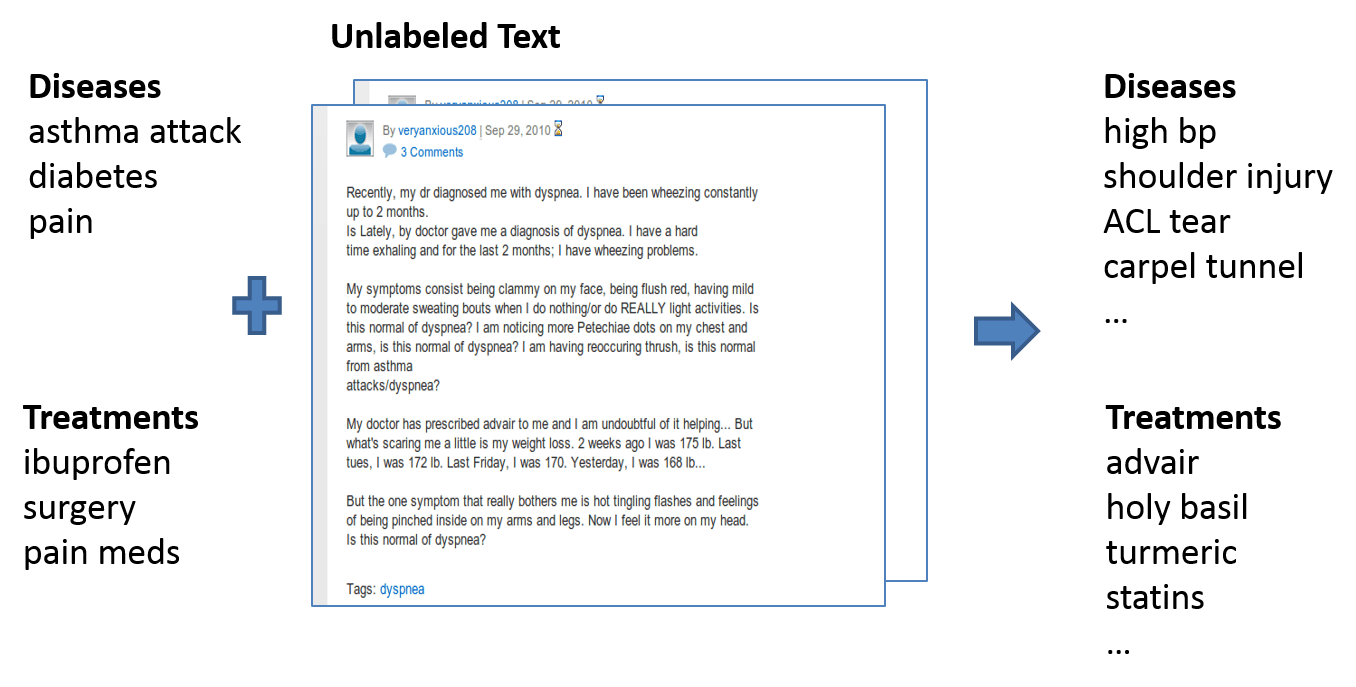
Input: seed sets (that is, dictionaries) of entities for some classes and unlabeled text.
Ouput: More entities belonging to the classes extracted from the text.
Algorithm: bootstrapped pattern-based learning.
Example input and output of the system
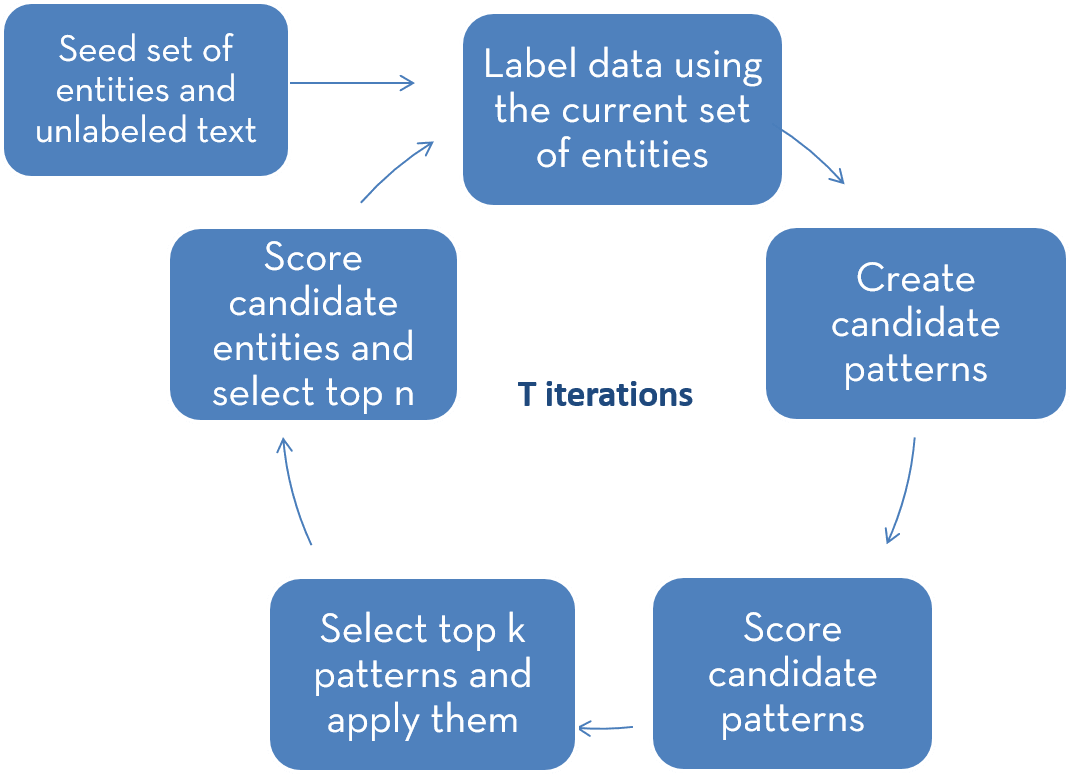
Algorithm
Demo
Citation
The pattern learning system is described in:
Improved Pattern Learning for Bootstrapped Entity Extraction. Sonal Gupta
and Christopher D. Manning. In Proceedings of the Eighteenth Conference on Computational Natural Language Learning (CoNLL). 2014.[pdf; Supplementary; bib]
Licensing
Please refer to the license for Stanford CoreNLP.
Downloads
The pattern-based learning code can be downloaded from the Stanford CoreNLP package (version >=3.4).Usage
- Download Stanford CoreNLP version >= 3.4
The main class is
edu.stanford.nlp.patterns.GetPatternsFromDataMultiClass. An example properties file ispatterns/example.propertiesand the example data is in the same directory. (If you are using version < 3.5.1, useedu.stanford.nlp.patterns.surface.GetPatternsFromDataMultiClassclass.) - Configuration
See the example properties file
patterns/example.propertiesfrom the code distribution as a basis. Change the HOME variable. The *** symbol in the properties file tells you which settings should be adjusted to fit your system; other ones can likely be left alone. For more details on the parameters and more parameters, see the javadoc. - Input
The input consists of a file or directory of text and files with seed sets of entities for each label. For an example, see the data in patterns directory -- in this example, we try to learn names of U.S. presidents and vice-presidents, names of their family members, and places they are related to from the text copied from the White House website.
- Output
The output files are the following, where $v means the value of the variable v in the properties file:
Inside $outDir/$identifier/$for-each-label , files
learnedwords.txt : learned words, iterations are separated by newlines
learnedpatterns.txt : learned patterns, iterations are separated by newlines
patterns.json : output json file for visualization
words.json : output json file for viusalization
tokensmatchedpatterns.json : output json file for visualization - Running
To run with your properties file:java -cp classpath edu.stanford.nlp.patterns.GetPatternsFromDataMultiClass -props yourproperties.properties
An example of how to run using the example data distributed with the code:java -cp stanford-corenlp-3.5.1.jar:stanford-corenlp-3.5.1-models.jar:javax.json.jar:joda-time.jar:jollyday.jar edu.stanford.nlp.patterns.GetPatternsFromDataMultiClass -props patterns/example.properties
FAQ
Please refer to this document for the commonly asked questions. Other questions Please email Sonal Gupta if you have other questions. The distribution is still in beta and likely in need of more testing so feel free to ask.
Visualization
Entity centric view
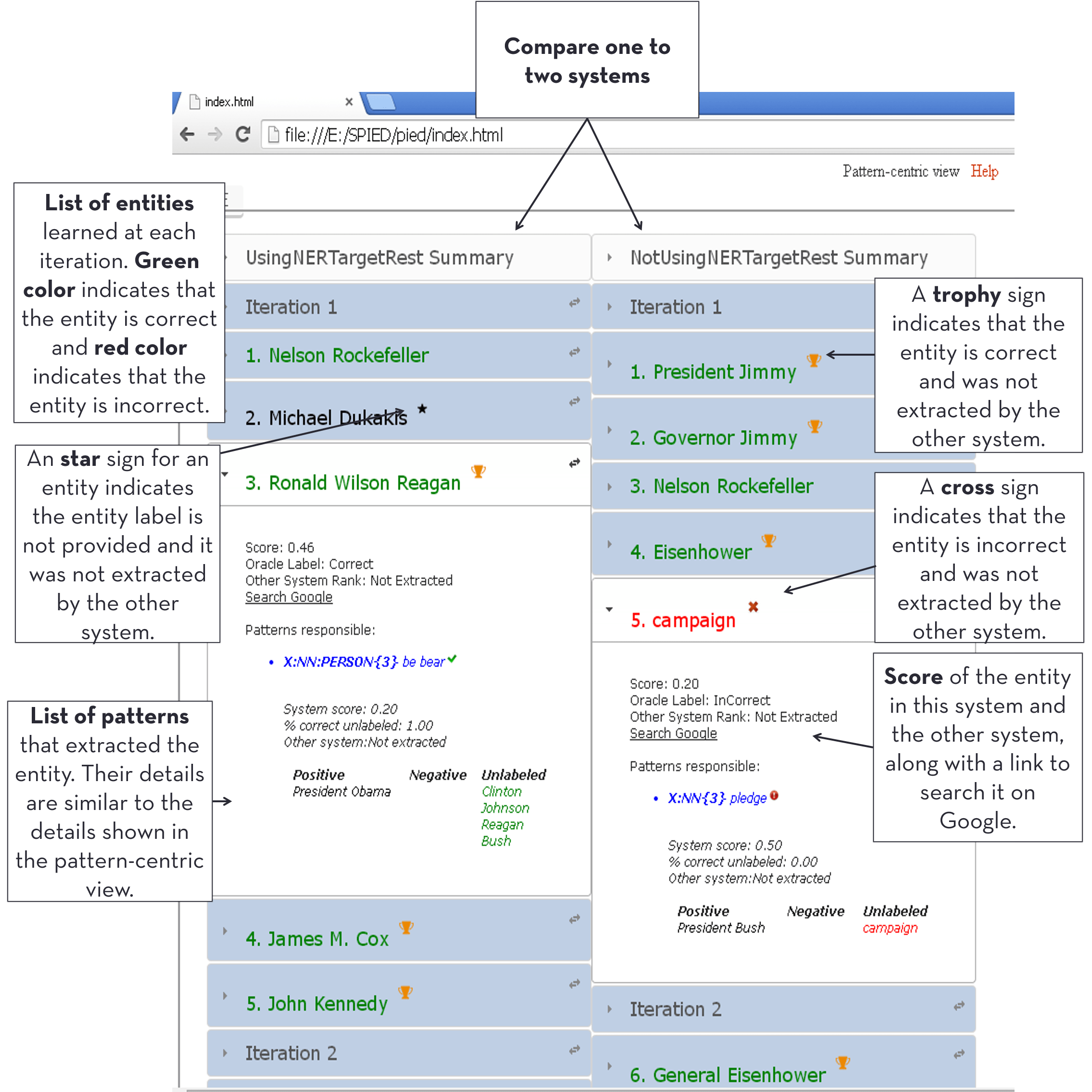
Pattern centric view

An earlier version of the visual interface is described in:
Sonal Gupta and Christopher D. Manning. 2014. SPIED: Stanford Pattern-based Information Extraction and Diagnostics. In Proceedings of the ACL 2014 Workshop on Interactive Language Learning, Visualization, and Interfaces (ACL-ILLVI). [pdf, bib]
SPIED-viz, the visualization part of SPIED, is licensed under the full GPL, which allows its use for research purposes, free software projects, software services, etc., but not in distributed proprietary software.
Download the code from GitHub.
See GitHub ReadMe file.
Release History
| Version 1.0 | July 1, 2014 | Initial release |