A Distributed Two-Tier Architecture for Multiple Domain Language Understanding:
Combining Call-Routing and Domain Specific Understanding to Increase
Performance, Location Independance and Scalability
Team Mobile
Alex Carobus (acarobus@cs.stanford.edu)
Jyoti Paul (jpaul@cs.stanford.edu)
1. Introduction
In current wireless devices (cellphones, PDA's, pagers, etc.) input is
often clumsy due to the size of these devices which makes it difficult
to give instructions and retrieve information. This has been one of the
greatest limiting factors in the growth of the mobile information device
market. Due to recent advances in voice technology, using natural
language understanding to navigate wireless applications is becoming a
more viable alternative to menus, pens, and keypads. However, in
order for this to be possible it is not only neccessary to convert speech
to text, but to have a system on the recieving end (client, gateway, etc.)
that can understand the text. The goal of such a system would be
to translate common speech into commands and queries, which would then be
executed and the user informed of the results either through speech or text.
Natural Language Understanding is one of the most difficult problems in
Artificial Intelligence (AI), getting a machine to be able to derive
meaning from a sentence on an arbitary subject has proved a very elusive
goal. This is further complicated by the ungramatical and often noisy
nature of spontaneous speech. However, work on systems that restrict
their understanding to only a small specialized domain has been somewhat
successful. In particular, systems have been developed that can converse
on a single subject such as the weather, stocks or airline reservations
nearly flawlessly. At the same time algorithms to determine the subject
of a particular sentence have also been developed for the purpose of
call-routing. Our idea was that by combining these algorithms we could c
reate a system which would be able to handle multiple domains with
greater success than has been previously been achieved.
Even besides the goal of increasing the performance of multiple domain
language understanding, our project attempts to show how our arcitechture
can easily be expanded or personalized to incorporate (or unincorporate)
new domains and does not require that the the understanding mechanisms for
different domains share the same location or even similar implementations.
These properties of scalability and location independance are very
important in the realm of wireless communications where users often have
different requirements for which information is important to them and
where this data is located.
2. Project Description
2.1 Architecture
The overall architecture of the system is shown below:
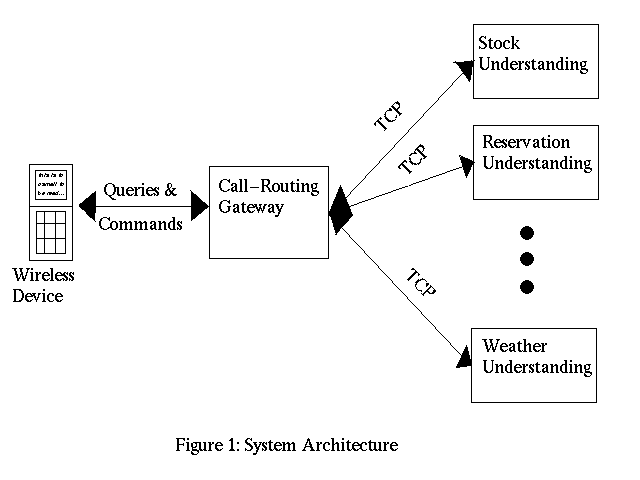 The system consists of two tiers. The first tier contains a gateway
whose purpose is to route commands and queries to the appropriate domain
specific language understanding engine. The second tier consists of these
engines. Since the two tiers communicate using TCP and since elements in
the second tier have no awareness of each other, they can be located
anywhere that is network accessible by the first tier. Once the gateway
decides which element of the second tier to which it will forward the
command or query, it merely acts as a conduit between the engine and the
user. This allows the implementation of the engines to be independant.
The system consists of two tiers. The first tier contains a gateway
whose purpose is to route commands and queries to the appropriate domain
specific language understanding engine. The second tier consists of these
engines. Since the two tiers communicate using TCP and since elements in
the second tier have no awareness of each other, they can be located
anywhere that is network accessible by the first tier. Once the gateway
decides which element of the second tier to which it will forward the
command or query, it merely acts as a conduit between the engine and the
user. This allows the implementation of the engines to be independant.
2.2 Call Routing
Call Routing is a problem that has been addressed by various research
work in the past. The problem involves routing phone calls to one of different
application domains in an environment with several application systems
running concurrently. The problem is similar to that of text categorization
in that it involves categorizing requests (calls) into groups with specific
destination. However, in addition to categorization, call routing adds
the notion of a session context. It is very likely that in a phone conversation
the caller would ask a question or a make a comment that follows the previous
question or comment.
Our approach overlaps with the work done by Jennifer Chu-Carroll and
Bob Carpenter at Bell Labs (Chu-Carroll and Carpenter, 1999) which to our
knowledge is one of the most extensive attempts within this topic. Chu-Carroll
and Carpenter uses a Vector-Based approach which uses document vectors
to categorize calls which are further disambiguated using a disambiguation
module. Failure in disambiguation lead calls to human operators. Our approach
shares the basic document vector notion in their work but further explore
history based disambiguation. This way we fully leverage any information
the system knows from the current context of the conversation. The call
router further consults the language understanding framework to acheive
query based disambiguation.
2.3 Single Domain Understanding Engines
The Single Domain Understanding Engines (SDUE) work by fitting a command or
query into one of a predeterminded set of frames. The engine takes the
sentence inputted by the user, extracts the important parts of it, finds
the frame to which the query or command corresponds and fill in the
fields in the frame with the information provided by the user. If the
engine determines it needs more information from the user before it can
carry out the appointed task, it will ask the user for further information
or clarification. When the SDUE decides it has enough information to
carry out the query or command it does so and returns the result to the
user. The SDUE uses some very simple heuristics to determine both which
frame to select and how to fill the fields, but since the domains are
small and very specific, powerful and robust techniques are not necessary.
3. Methods
3.1 Call Routing
The call routing system is made up of two main parts- the training module
and the real time routing module. The training module uses domain specific
knowledge to train the router and assist in document vector generation.
The routing module creates an on-the-fly pseudo document from the request
(call) and uses similarity measures to determine the appropriate application
domain (which runs its own language understanding system) for forwarding.
The training module uses one document per destination (application domain).
In the system we implemented this include a stock management domain and
an airline reservation domain (with data from ATIS). The module starts
with a simple morphological filtering process followed by a round where
an ignore list is applied. This is followed by the n-gram vector extraction
process. The algorithm involves extraction of all unigrams and bigrams
from the destination documents. In addition a Term-Document matrix (n-gram
terms and destination documents) is generated with the frequency of the
terms in the documents. We follow this process by a normalization process
so that each term vector is of unit length. This ensures that terms that
occurs more frequently in the training corpus does not get more weight.
If A(t, d) is a matrix element before normalization, it is altered as follows:
A(t, d)
B(t, d) = -----------------------------------------
Sqrt(Sum(A(t, e)*A(t, e)) for all 1<=e<=n)
We use another weighting factor which encapsulates the notion that
a term that occurs in a few documents is more important in routing than
a term which occurs in many more documents. The factor, called inverse-document
frequency is defined as follows:
IDF(term)= log (n/d(t))
where n is the number of documents and d(t) is the number of documents that include the term.
The two factors are finally combined to calculate the Term-Document
Matrix values.
C(t, d) = IDF(t)*B(t, d)
The routing module consists of two steps, the psuedo document generation
step and the similarity measure step. In the first step a pseudo document
is generated with all the terms (unigrams and bigrams) from the caller
request and their frequencies. Simple morphological filtering and ignore
lists are applied, followed by extraction of n-grams. The fact that higher
n-gram terms are better indicators of potential destination is utilized
by giving a higher wieght to bigrams (w=2, w=1 for unigrams). The vector
generated is added to the training matrix to provide on-going learning.
The next step of candidate destination selection using similarity measures
is fairly simple. We measure similarity between the pseudo-document vector
and the document vectors in the Term-Destination Matrix to determine the
application domain for forwarding. Cosines offered a good similarity measure
solution in our implementation.
A major improvement we provided over the Chu-Carroll and Carpenter system
is the session history implementation. For every session (conversation
with a phone user), we create and maintain a history array for every document.
These arrays encapsulate the use of various application domains over the
session and the history arrays are consulted to bias routing towards domains
used heavily earlier in the session. This approach especially helps when
the scores for different domains vary by a small margin. The term values
in the document vectors is altered in this implementation as follows:
V(i, d) = Sum(alpha^(i-k)*w(k, d)) for all 0=<k<=i
where V(i, d) is the value of the matrix element, w(k, d) is the value of a history element, d
is the document index, i is the term index and alpha is the session history coefficient.
3.2 Single Domain Understanding Engines
The implementation of the SDUE's is based on the work done on by Roberto
Pieraccini et al. on the CHRONUS system. The algorithm works in a number
of the stages starting with a sentence of natural language and creating a
query to a database. For the purpose of this project, since we do not
have access to any databases of information for our domains, we
merely output the database query and use this as the measure of the
success of the system. The two SDUE's we implemented were a
system for querying about airline flight schedules, the meal served on the
flight and the cost of the ticket and a system for buying, selling and
getting quotes on stocks. The program itself had no domain specific code,
instead the word classes and frames (explained below) which fully describe
a domain in our implementation were merely datafiles read in at run time.
This allows for quick creation of new SDUE's for new domains.
The first stage in the SDUE consists of lexical analysis of the query or
command. The purpose of this is to determine which, if any, of the word
classes that every word in the query belongs to. For example, this stage
will determine that "Philadelphia" is a city and and mark it as such and
will discard words such as "the" and "a" which are not used in determining
the meaning of the sentence. The word classes are different for every
domain which is one of the reasons that SDUE's can be more successful than
Multi Domain Understanding Engines (MDUE), there is much less ambiguity to
disambiguate. For example, in the
flight reservation system "Continental" is listed as type airline and in
the stock system it is listed merely as a company which has public stock.
This makes it easy for the SDUE to decide what constraint the user wants
to place on the results returned.
The second stage of the SDUE consists of the conceptual decoder, this part
of the system attempts to remove the ambiguity that still exists in the
single domain. For example, even after it has determined that
"Philadelphia" is a city, it is not known whether this is the user's
desired destination, departure city or stopover city. The conceptual
decoder resolves such ambiguities by using key words that precede the
word. For example, when a city is preceded by the word "to" it can be
assumed to be the destination. The CHRONUS system calculates these
probabilities by training a Hidden Markov Model on a set of tagged
training data. Since tagged data was not available to us and we
handcrafted these probabilities using the data available as a guide, the
implications of this will be discussed in the Analysis section.
In the third stage of the processing, the algorithm selects the frame
which it believes represents the query being asked by the user based on
the perceived subject of the sentence. The SDUE fills in the information
in the frame with the fields created by the conceptual decoder. A frame
is a heirarchical structure which contains information which is both
required for a database query and can be optionally added. An simple example
frame from the stock system looks thus:
{
|Buy subject
|Company company
|Shares number
{
|Price number
}
}
This is interpreted as a "Buy" request, it has two parameters which are
required, the company and number of shares, and a third which is optional,
the maximum price the user is willing to pay. Each field has a type which
it must be. By filling in this frame, the algorithm changes a human
readable sentence into a machine readable query.
The last stage in processing is the interpreter, at this stage the
algorithm decides
if it should make the query or seek more information before it does.
There are two possible sources of new information, the previous queries
that the user has made to the system and the user himself. If the system
can find the data for an empty field that is required for the query in a
previous query, it will incorporate this data. If the data is not a
required field, it is not clear when to incorporate this data and when not
to. A number of heuristics were tested, the one that worked the best for
both systems was to incorporate the all the fields of the previous query
as long as none of the required fields of the query have changed. If the
algorithm can not find the necessary data element in this way, it will
ask the user to provide the data for it before he makes the the query.
This is the job of the interpreter.
The end result is a frame which describes a query to the database. Again,
it is worth emphasizing that all the word classes and frames are merely
data files and are not hardcoded, they can be quickly changed to create
new possible queries or new elements in the class.
4. Results
3.1 Call Routing
Comparison of basic call routing with call routing with session history:
|
Basic Routing
|
alpha=0.05
|
alpha=0.075
|
alpha=0.1
|
alpha=0.3
|
alpha=0.5
|
|
83%
|
87%
|
87%
|
87%
|
77%
|
53%
|
Table 1: Routing accuracy
The above tests were done on a document containing 49 questions and comments
chosen randomly from the stock management domain and the airline
reservation domain. The results show the percentage of requests that were
forwarded accurately to their respective domains. The basic routing is our
regular call routing implementation, while those with alpha values are
ones using the session context history. See Methods for an explanation on
alpha.
The raw data is attached in Appendix B.
3.2 Single Domain Understanding Engines
The results of the tests on four different data files are shown below:
|
Correct |
Correct after asking questions |
Correct but more data returned than requested |
Incorrect due to missing variable or domain |
Incorrect |
| ATIS data (abridged) |
42 |
7 |
0 |
0 |
1 |
| ATIS data (unabridged) |
23 |
4 |
7 |
11 |
4 |
| Stock data |
31 |
19 |
0 |
0 |
1 |
| Combined data (abridged) |
72 |
17 |
0 |
0 |
11 |
Table 2: Results of Single Domain Understanding Engines
The ATIS data sets were both run using the same word classes and frames.
The Stock data set used a stock word class and frame file. The combined
test used the concatenation of the ATIS and stock files. The abridged
data contained a random selection of queries from the ATIS data set which
consists only of the variables described in the frames file (in
particular, flight numbers and aircraft types where not implemented). The
unabridged ATIS testing file contained queries randomly selected from the
ATIS dataset regardless of variables used. The stock data was fake data
created for this project and the combinded data was the concatination of
the data files.
A query was marked "Correct" when it selected the correct frame and added
all relevent data to the frame. A query was marked "Correct after asking
questions" if found and correctly filled the frame only after asking
questions of the user, in about ninty percent of these cases asking the
user was the only way to attain the data necessary to complete a correct
frame. A frame was marked "Correct but more data returned than requested"
if it returned what was requested and more, for example if the user asked
for the cheapest fare and all fares were returned. A query was marked
"Incorrect due to missing variable or domain" if it was unable to find and
fill the frame correctly because it lacked the information necessary,
often this can be corrected by adding word classes and frames. Lastly, a
query was marked "Incorrect" if the wrong frame or incorrect data was
selected.
The raw data is attached in Appendix A.
5. Analysis
3.1 Call Routing
We performed extensive testing to compare our basic call routing approach
with the variation including session history. This also included determination
of an optimal session history coefficient (alpha) value. It is evident
from out test results that use of an appropriate alpha value (0.05 to .01
in our implementation) leads to better results than the regular approach.
In general our implementation led to fairly satisfactory results. We
acheived 87% accuracy for all call routing including ambiguous samples,
with an optimal alpha value. Chu-Carroll and Carpenter reported a 93.8%
accuracy using sophisticated morphological filtering software and various
other comprehensive ignore lists and stop word filters. In addition, we
believe that our system's performance can be significantly improved by
providing larger training sets. Our training sets (especially for stock
management questions) were fairly limited in size.
In our training process we used various selectivity factors to drain
out less influencial unigrams and bigrams. Our results showed that eliminating
unigrams and bigrams which occur only once had a positive effect. However
when the threshold was increased the routing process suffered significantly.
A reason for this is the limited size of our corpus (especilly stock management),
for a larger corpus over all domains a higher selectivity frequency will
work better.
3.2 Single Domain Understanding Engines
The first thing that is obvious from the results is that the SDUE's are
very successful on logically single domains when the queries can be
represented in the frames (i.e. there are no variables or domain elements
in the query that does not have a representation in the wordclass and/or
frame). In both of these cases (unabridged and stock
data), the algorithm only gets a single query incorrect. The failures on
the unabridged ATIS data are a result of concepts that are not represented
in the data files fed into the SDUE, if these concepts were represented
there is no reason to believe that they would not be successfully framed.
The fact that the failures go from 2 to 11 when the frames and data are
combinded for the stock and flight data, shows that by keeping the domains
seperate, performance is greatly enhanced.
Although the simplification of using hand created frame files rather than
having them generated by an HMM might be seen to make the system less
robust and useful, it is in fact very simple to create a SDUE for a
domain and the performance is as good as can be expected on the test
cases run.
3.3 System
Overall, we have shown that a system constructed using the architecture
described above can be expected to perform and scale very well. The
decompisiton of the understanding into single domains allows for even a
set of weak language understanders to combine using a call-router to form
a overall robust and powerful system.
6. Conclusions
It is evident from our results that a distributed natural language processing
system for multiple application services works significantly better than
a powerful centralized version. Even a weak language understanding module
for a particular service performs better in handling calls in that domain
than a powerful generalized version. Our architecture utilizes this fact
without sacrificing the span of a generalized system. Our use of sophisticated
call routing makes the distributed architecture transparent to the end-user,
who can still call a single system (phone number) for all the services.
References
[1] Chu-Carroll, J. and Carpenter, B., "Dialogue Management in Vector-Based
Call Routing,"
Computational Linguistics,
1998.
[2] Levin, E. and Pieraccini, R., ``A stochastic model of computer-human
interaction for learning dialogue
strategies,'' Proc. of EUROSPEECH 97, Rhodes,
Greece, Sept. 1997.
[3] Pieraccini, R., Levin, E. and Eckert, W., ``AMICA: the AT&T
Mixed Initiative Conversational
Architecture,'' Proc. of EUROSPEECH 97, Rhodes,
Greece, Sept. 1997.
[4] Pieraccini, R. and Levin, E., ``A spontaneous-speech understanding
system for database query applictions,''
ESCA Workshop on Spoken Dialogue Systems -
Theories & Applications, May/June 1995.
[5] Levin, E. and Pieraccini, R., ``CHRONUS, the next generation,''
Proc. 1995 ARPA Spoken Language Sstems
Tech. Workshop, Austin, Texas, Jan. 1995.