The Unsupervised Language Learning Project Page
Overview
Humans are able to acquire linguistic knowledge in a more or less unsupervised manner. Although machines lack the contextual situation of a human learner, as well as whatever innate knowledge humans might have, much of the structure of natural language is distributionally detectable. The more linguistic structure that can be automatically learned, the less need there is for large marked-up corpora, which are costly in both time and expertise.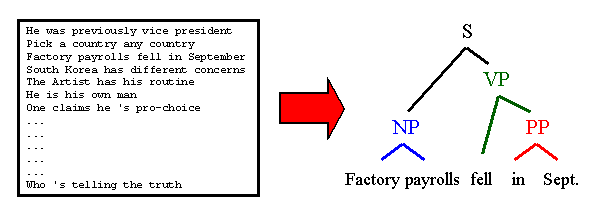
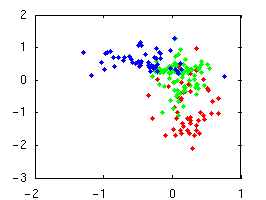
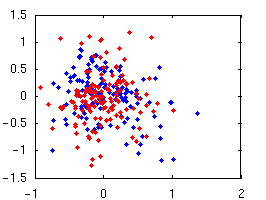
Our primary focus is on grammar induction, which aims to find the hierarchical structure of natural language. Grammar search methods have met with little success, and simple distributional approaches that work for part-of-speech induction do not directly apply. For example, differentiating noun phrases, verb phrases, and prepositional phrases requires discovering the three clusters in the left plot -- which seems easy enough. However, deciding which sequences are units at all requires telling apart the red and blue clusters on the left -- which is much harder.
|
|
| Labeling constituents is easy. | Finding constituents is hard. |
However, using a constituent-context model, which essentially allows distributional clustering in the presence of no-overlap constraints, we can successfully recover a substantial amount of hierarchical structure, even with just a few thousand training sentences. Our system gives the best published results for unsupervised parsing of the ATIS corpus, and, in particular, was the first system to beat a baseline of putting right-branching over English text (measures as unlabeled constituent F1; see Klein and Manning, 2001, 2002).
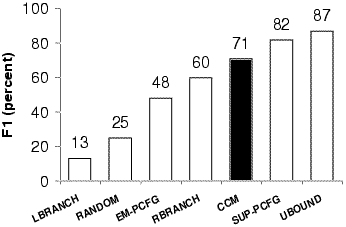
Induced trees are substantially better than even the supervised right-branching baseline.
A complementary approach to induction is to focus on relationships between word pairs, or dependencies. Previous work using this approach was quite unsuccessful because it used too simple a dependency model. Our model, borrowing ideas of word classes and valence from supervised parsing dependency models, performs well above baseline. Combining it with the CCM model via a factored model gives extremely good results, as shown below.

Incorporation of the dependency model substantially improves performance, closing in on the performance achieved by supervised parsers (92.8% for English).
However, interesting issue remain ranging from dealing better with languages like Chinese that largely lack morphology and function words, to making substantive use of morphology in languages with rich morphology.
Publications
| Trond Grenager and Christopher D. Manning. 2006. Unsupervised Discovery of a Statistical Verb Lexicon. 2006 Conference on Empirical Methods in Natural Language Processing (EMNLP 2006), pp. 1-8. http://nlp.stanford.edu/~manning/papers/verblex.pdf | ps |
|
| Dan Klein and Christopher D. Manning. 2004. Corpus-Based Induction of Syntactic Structure: Models of Dependency and Constituency. Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics (ACL 2004). http://nlp.stanford.edu/~manning/papers/factored-induction-camera.pdf | ps | |
| Dan Klein and Christopher D. Manning. 2002. A Generative Constituent-Context Model for Improved Grammar Induction. Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pp. 128-135. http://nlp.stanford.edu/~manning/papers/KleinManningACL2002.pdf | ps | |
| Dan Klein and Christopher D. Manning. 2002. Natural Language Grammar Induction using a Constituent-Context Model. In Thomas G. Dietterich, Suzanna Becker, and Zoubin Ghahramani (eds), Advances in Neural Information Processing Systems 14 (NIPS 2001). Cambridge, MA: MIT Press, vol. 1, pp. 35-42. http://nlp.stanford.edu/~manning/papers/nips-gi-camera-mt.pdf | ps | |
| Dan Klein and Christopher D. Manning. 2001. Distributional Phrase Structure Induction. Proceedings of the Fifth Conference on Natural Language Learning (CoNLL-2001), pp. 113-120. http://nlp.stanford.edu/~manning/papers/klein_and_manning-distributional_phrase_structure_induction-CoNLL_2001.pdf | ps |
Contact
Comments about the project page? Feel free to email
Chris.