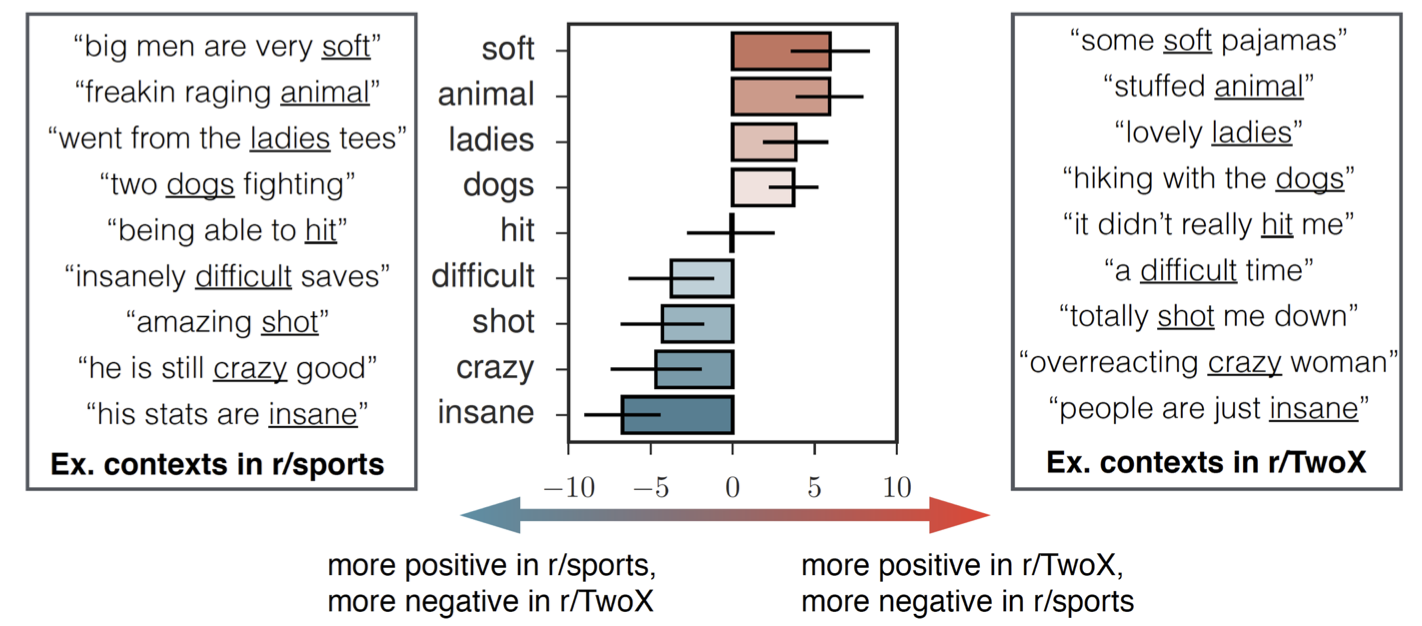
The word soft may evoke positive connotations of warmth and cuddliness in many contexts, but calling a hockey player soft would be an insult.
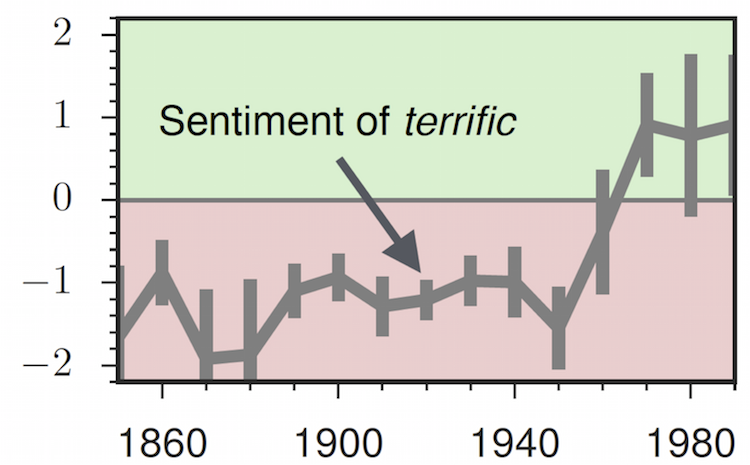
If you were to say something was terrific in the 1800s, this would probably imply that it was terrifying and awe-inspiring; today, terrific basically just implies that something is (pretty) good.
A word's sentiment or connotation depends on the domain or context in which it is used.
However, previous computational work in natural language processing largely ignores this issue, and focuses and building and deploying generic domain-general sentiment lexicons.
SocialSent is a collection of code and datasets for performing domain-specific sentiment analysis.
The SocialSent code package contains the SentProp algorithm for inducing domain-specific sentiment lexicons from unlabeled text, as well as a number of baseline algorithms.
We have also released domain-specific historical sentiment lexicons for 150 years of English and community-specific sentiment lexicons for 250 "subreddit" communities from reddit.com.
The historical lexicons reveal that more than 5% of sentiment-bearing words switched their polarity from 1850 to 2000,
and the community-specific lexicons highlight how sentiment varies drastically between online communities.
The paper Inducing Domain-Specific Sentiment Lexicons from Unlabeled Corpora details the SentProp algorithm and describes the lexicons we induced.
Getting started (Code download)
All the code is available
on GitHub
Domain-specific sentiment lexicons for download
1. Community-specific sentiment lexicons for the 250 largest subreddit communities from reddit.com
Community-specific lexicons are available here.
Each lexicon contains sentiment values for the top-5000 non-stop words in each community (there may be less than 5000 after removing the stop-words, however).
The lexicons were constructed using all public comment data from the year 2014.
The included README in the download file contains more info.
2. Historical sentiment lexicons for the last 150 years of English (by decade)
We provide two varieties of historical sentiment lexicons:
The included READMEs in the download files contains more info.
Both the lexicons were constructed using the Corpus of Historical American English.
This data is made available under the Public Domain Dedication
and License v1.0 whose full text can be found at:
http://www.opendatacommons.org/licenses/pddl/1.0/.
William L. Hamilton, Kevin Clark, Jure Leskovec, and Dan Jurafsky.
Inducing Domain-Specific Sentiment Lexicons from Unlabeled Corpora.
ArXiv preprint (arxiv:1606.02820). 2016.
1. Word sentiment varies drastically between online communities
Word sentiment differs drastically between a community dedicated to sports (r/sports) and one dedicated to
female perspectives and gender issues (r/TwoX). Words like soft and animal have positive sentiment in r/TwoX but negative
sentiment in r/sports, while the opposite holds for words like crazy and insane.
2. Word sentiment varies dramatically over historical time-periods
Historical sentiment lexicons reveal how words have changed in their connotation over time.
Our analysis shows that around 5% of sentiment-bearing (non-neutral) words switched polarity between 1850 and 2000.
For example, we found that
- Pathetic became more negative. It used to be similar in meaning to passionate but gained connotations of "weakness" over time.
- Lean became more positive. It used to be associated with "weakness" or "frailty", but over time it become more associated with "fitness" and "muscularity".
Semantic similarities computed using word vector embeddings were used to contextualize these shifts (e.g., showing that
pathetic became more semantically similar to
weak).
GitHub: SocialSent is on
GitHub. For bug reports and patches, you're best off using the
GitHub Issues and Pull requests features.