Introduction
TACRED is a large-scale relation extraction dataset with 106,264 examples built over newswire and web text from the corpus used in the yearly TAC Knowledge Base Population (TAC KBP) challenges. Examples in TACRED cover 41 relation types as used in the TAC KBP challenges (e.g., per:schools_attended and org:members) or are labeled as no_relation if no defined relation is held. These examples are created by combining available human annotations from the TAC KBP challenges and crowdsourcing.
Please see our EMNLP paper, or our EMNLP slides for full details.
Note: There is currently a label-corrected version of the TACRED dataset, which you should consider using instead of the original version released in 2017. For more details on this new version, see the TACRED Revisited paper published at ACL 2020.
Examples
TACRED was created by sampling sentences where a mention pair was found from the TAC KBP newswire and web forum corpus.
In each TACRED example, the following annotations are provided:
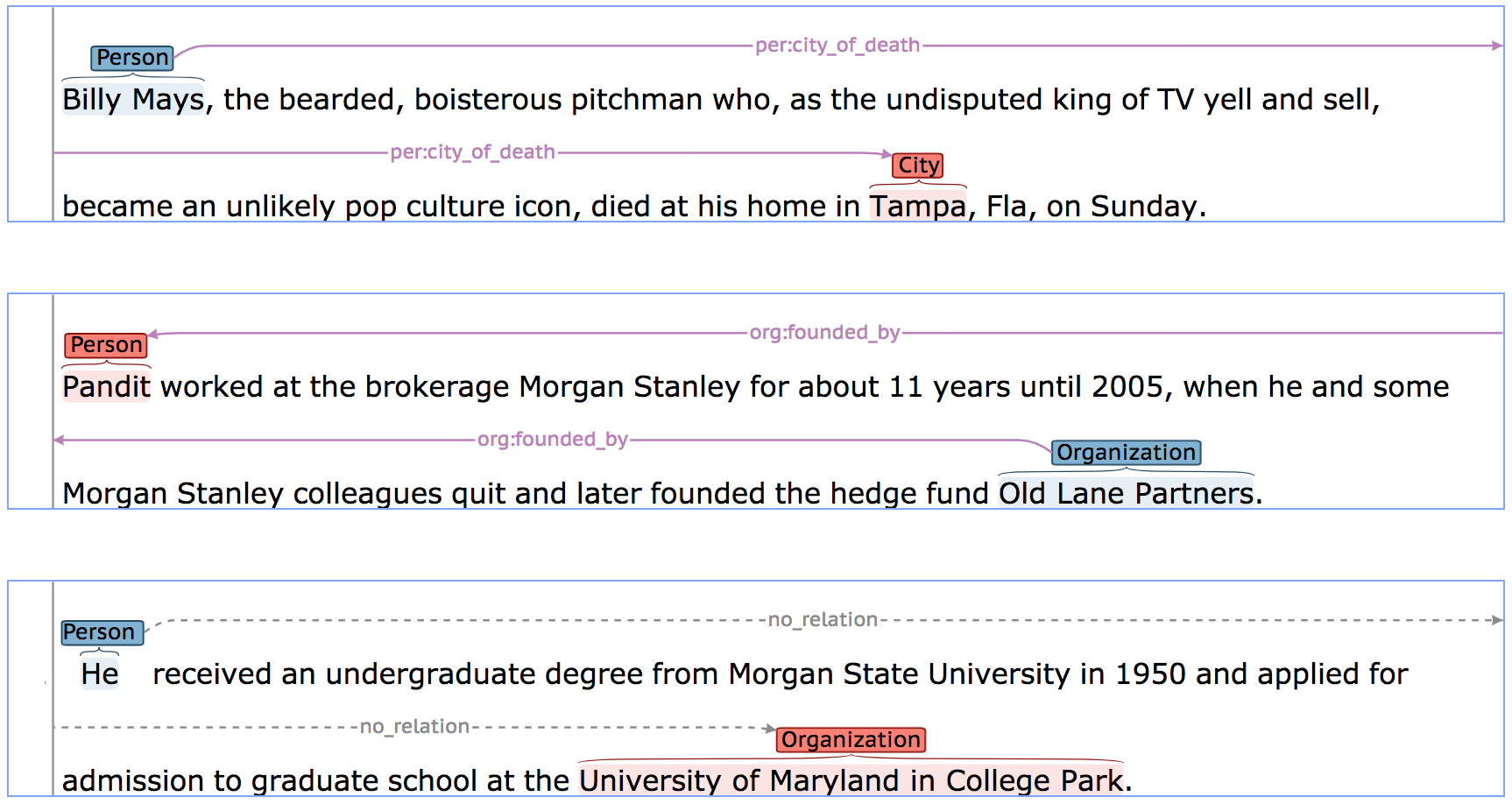
Below are samples from the TACRED dataset:
Data Statistics
To miminize dataset bias, we stratify TACRED across years in which the TAC KBP challenge was run:
| Split | Number of Examples | Original Corpus |
|---|---|---|
| Train | 68,124 | TAC KBP 2009–2012 |
| Dev | 22,631 | TAC KBP 2013 |
| Test | 15,509 | TAC KBP 2014 |
To ensure that models trained on TACRED are not biased towards predicting false positives on real-world text, we fully annotated all sampled sentences where no relation was found between the mention pairs to be negative examples. As a result, 79.5% of the examples are labeled as no_relation. Among the examples where a relation was found, the distribution of relations is:
Compared to previous relation extraction datasets, TACRED contains longer sentences with an average sentence length of 36.4, reflecting the complexity of contexts in which relations occur in real-world text.
Dataset Usage
TACRED was created with the aim to advance the research of relation extraction and knowledge base population. Therefore at Stanford, we've been using TACRED to (1) benchmark relation extraction models, and (2) train our knowledge base population systems.
We found that carefully-designed neural models when trained on TACRED can easily outperform patterns or traditional models with manual features.
| Model | P | R | F1 | |
|---|---|---|---|---|
| Traditional | Patterns | 86.9 | 23.2 | 36.6 |
| Logistic Regression (LR) | 73.5 | 49.9 | 59.4 | |
| LR + Patterns | 72.9 | 51.8 | 60.5 | |
| Neural | CNN | 75.6 | 47.5 | 58.3 |
| LSTM | 65.7 | 59.9 | 62.7 | |
| LSTM + Position-aware attention | 65.7 | 64.5 | 65.1 |
We found that our TACRED-powered new KBP system beats the previous state-of-the-art by a large margin.
| System | Hop-0 | Hop-0 + Hop-1 | ||||
|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | |
| 2015 Winning System (LR + Patterns) | 37.5 | 24.5 | 29.7 | 26.6 | 19.0 | 22.2 |
| Our Neural System (trained with TACRED) | 39.0 | 28.9 | 33.2 | 28.2 | 21.5 | 24.4 |
| + Patterns | 40.2 | 31.5 | 35.3 | 29.7 | 24.2 | 26.7 |
For details on the models and experiments, please check out our EMNLP paper.
Access
To respect the copyright of the underlying TAC KBP corpus, TACRED is released via the Linguistic Data Consortium (LDC). Therefore, you can download TACRED from the LDC TACRED webpage. If you are an LDC member, the access will be free; otherwise, an access fee of $25 is needed.
Note: In addition to the original version of TACRED, you should also consider using the new label-corrected version of the TACRED dataset, which fixed a substantial portion of the dev/test labels in the original release. For more details, see the TACRED Revisited paper and their code base.
If you are affiliated with Stanford University, you are most likely qualified for free access of the data. Please contact Stanford Corpus TA for details on how to access the data.
Code
To get started on using TACRED or run the baseline position-aware attention model, you can use our PyTorch code .
Citation
Please cite the following paper if you use TACRED in your research:
@inproceedings{zhang2017tacred,
author = {Zhang, Yuhao and Zhong, Victor and Chen, Danqi and Angeli, Gabor and Manning, Christopher D.},
booktitle = {Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing (EMNLP 2017)},
title = {Position-aware Attention and Supervised Data Improve Slot Filling},
url = {https://nlp.stanford.edu/pubs/zhang2017tacred.pdf},
pages = {35--45},
year = {2017}
}
Contact Us
If you have questions using TACRED, please email us at: