Software > CoreNLP Spanish FAQ
Spanish FAQ for Stanford CoreNLP, parser, POS tagger, and NER
Questions
- How do I use the Spanish CoreNLP pipeline?
- What corpus was used to train the CoreNLP Spanish models?
- How did you modify the AnCora corpus?
- How does CoreNLP tokenize Spanish text?
- What character encoding do you assume?
- What POS tag set does the parser use?
- What phrasal category set does the parser use?
- How well do the parsers work?
- Is there a Spanish dependency parser?
- Where does the Spanish-specific source code live?
Questions with answers
How do I use the Spanish pipeline?
What corpus was used to train the CoreNLP Spanish models?
We trained and evaluated our Spanish models on a combination of two corpora, after very heavy modifications (described further below):
- AnCora Spanish 3.0 corpus. This corpus consists of about 17,000 sentences, drawn from Spanish (Spain) newswire and from an older balanced Castilian Spanish corpus (3LB).
- The DEFT Spanish Treebank V2 (LDC2015E66). This corpus contains the full International Spanish Newswire Treebank and the full Latin American Spanish Discussion Forum Treebank (roughly 5,000 sentences in total).
This data was added to train the new Spanish models released in CoreNLP 3.7.0.
How did you modify the combined corpus?
(For those interested in as much detail as possible on these modifications, here is a 5-page document we wrote about these changes, with lots of pretty trees.)
We made three significant changes to the treebanks:
- Part-of-speech tagset simplification. The default AnCora tagset has hundreds of different extremely precise tags. This may be useful for some linguistic applications, but did not bode well for even a state-of-the-art part-of-speech tagger. We reduced the tagset to 85 tags, a more manageable size that still allows for a useful amount of precision. The tags are listed in a later answer.
- Multi-word expression expansion. The AnCora corpus is full of multi-word expressions: tokens which actually contain multiple words, linked by an underscore character. Some examples follow:
- no_obstante (idiomatic expression)
- Chris_Woodruff (person name)
- stock_options (foreign phrases)
- 31_de_julio (dates)
- 2,74_por_ciento (quantifier expressions)
These multi-word expressions have some fairly valid uses (e.g., for proper nouns and foreign words, where we can't be certain about the syntax of the constituent words), but also seem to be used as a crutch in places where the annotation rules were not sufficient (e.g., quantifier expressions, idiomatic expressions).
- Word splitting. Spanish sometimes contracts meaningful free morphemes into a single word. We expand these joined forms (namely clitic pronouns and prepositional contractions) to match our tokenization practices. See the answer on tokenization for more information.
There are some significant consequences in our tree representations. See an example of the effect of a contraction split below:
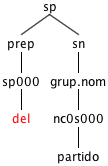
Before expansion. The word del is marked as a preposition, although it contains a form -l which acts as an article.
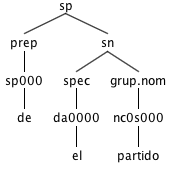
After expansion. The word del has been split into its constituent morphemes de and el. Note that el moves to a different tree constituent, into the proper position for an article.
How does CoreNLP tokenize Spanish text?
We tokenize exactly the same as we do for English, with a few exceptions. Below are listed notable features of our Spanish tokenization:
- Clitic pronouns are separated from their verbs. Spanish verbs can carry clitic pronouns in some cases (specifically, when the verb is a gerund, non-negative imperative, or infinitive form). The tokenizer separates the pronouns attached to the end of these verb types into separate tokens.
For example, negarse is tokenized to negar se — two separate tokens.
- Contractions are expanded into multiple words. Spanish contractions include e.g. al, del, conmigo, and consigo. The tokenizer expands these contractions into dictionary forms a el, de el, con mí, con sí, and so on. These expansions are grammatically incorrect at the surface level, but are very useful for all tasks following tokenization (tagging and parsing, for example).
- Parentheses are rendered =LRB= and =RRB=.
- All single quote forms (single curly quotes, single guillemets) are normalized to '; all double quote forms (double curly quotes, double guillemets) are normalized to ".
- Em dashes (—) and en dashes (–) are both normalized to --.
- Clitic pronouns are separated from their verbs. Spanish verbs can carry clitic pronouns in some cases (specifically, when the verb is a gerund, non-negative imperative, or infinitive form). The tokenizer separates the pronouns attached to the end of these verb types into separate tokens.
What character encoding do you assume?
We expect input in UTF-8 encoding. Behavior is otherwise undefined! (This mainly matters for the several accented letters and special punctuation characters used in Spanish.)What POS tag set does the parser use?
Currently, the only Spanish tagger model available is the Universal Dependencies model. This uses standard UPOS tags.
Prior to CoreNLP 4.0, we used a simplified version of the tagset used in the AnCora 3.0 corpus / DEFT Spanish Treebank. The default AnCora tagset has hundreds of different extremely precise tags. This may be useful for some linguistic applications, but did not bode well for even a state-of-the-art part-of-speech tagger. We reduced the tagset to 85 tags, a more manageable size that still allows for a useful amount of precision.
The tags are designed to remain compatible with the EAGLES standard. In our tags, we simply null out most of the fields (using a label 0) that are not relevant for our purposes. The resulting compressed tagset is listed below.
Tag Description Example(s) Adjectives ao0000 Adjective (ordinal) primera, segundo, últimos aq0000 Adjective (descriptive) populares, elegido, emocionada, andaluz Conjunctions cc Conjunction (coordinating) y, o, pero cs Conjunction (subordinating) que, como, mientras Determiners da0000 Article (definite) el, la, los, las dd0000 Demonstrative este, esta, esos de0000 "Exclamative" (TODO) qué (¡Qué pobre!) di0000 Article (indefinite) un, muchos, todos, otros dn0000 Numeral tres, doscientas do0000 Numeral (ordinal) el 65 aniversario dp0000 Possessive sus, mi dt0000 Interrogative cuántos, qué, cuál Punctuation f0 Other &, @ faa Inverted exclamation mark ¡ fat Exclamation mark ! fc Comma , fca Left bracket [ fct Right bracket ] fd Colon : fe Double quote " fg Hyphen - fh Forward slash / fia Inverted question mark ¿ fit Question mark ? fp Period / full-stop . fpa Left parenthesis ( fpt Right parenthesis ) fra Left guillemet / angle quote « frc Right guillemet / angle quote » fs Ellipsis ..., etcétera ft Percent sign % fx Semicolon ; fz Single quote ' Interjections i Interjection ay, ojalá, hola Nouns nc00000 Unknown common noun (neologism, loanword) minidisc, hooligans, re-flotamiento nc0n000 Common noun (invariant number) hipótesis, campus, golf nc0p000 Common noun (plural) años, elecciones nc0s000 Common noun (singular) lista, hotel, partido np00000 Proper noun Málaga, Parlamento, UFINSA Pronouns p0000000 Impersonal se se pd000000 Demonstrative pronoun éste, eso, aquellas pe000000 "Exclamative" pronoun qué pi000000 Indefinite pronoun muchos, uno, tanto, nadie pn000000 Numeral pronoun dos miles, ambos pp000000 Personal pronoun ellos, lo, la, nos pr000000 Relative pronoun que, quien, donde, cuales pt000000 Interrogative pronoun cómo, cuánto, qué px000000 Possessive pronoun tuyo, nuestra Adverbs rg Adverb (general) siempre, más, personalmente rn Adverb (negating) no Prepositions sp000 Preposition en, de, entre Verbs va00000 Verb (unknown) should vag0000 Verb (auxiliary, gerund) habiendo vaic000 Verb (auxiliary, indicative, conditional) habría, habríamos vaif000 Verb (auxiliary, indicative, future) habrá, habremos vaii000 Verb (auxiliary, indicative, imperfect) había, habíamos vaip000 Verb (auxiliary, indicative, present) ha, hemos vais000 Verb (auxiliary, indicative, preterite) hubo, hubimos vam0000 Verb (auxiliary, imperative) haya van0000 Verb (auxiliary, infinitive) haber vap0000 Verb (auxiliary, participle) habido vasi000 Verb (auxiliary, subjunctive, imperfect) hubiera, hubiéramos, hubiese vasp000 Verb (auxiliary, subjunctive, present) haya, hayamos vmg0000 Verb (main, gerund) dando, trabajando vmic000 Verb (main, indicative, conditional) daría, trabajaríamos vmif000 Verb (main, indicative, future) dará, trabajaremos vmii000 Verb (main, indicative, imperfect) daba, trabajábamos vmip000 Verb (main, indicative, present) da, trabajamos vmis000 Verb (main, indicative, preterite) dio, trabajamos vmm0000 Verb (main, imperative) da, dé, trabaja, trabajes, trabajemos vmn0000 Verb (main, infinitive) dar, trabjar vmp0000 Verb (main, participle) dado, trabajado vmsi000 Verb (main, subjunctive, imperfect) diera, diese, trabajáramos, trabajésemos vmsp000 Verb (main, subjunctive, present) dé, trabajemos vsg0000 Verb (semiauxiliary, gerund) siendo vsic000 Verb (semiauxiliary, indicative, conditional) sería, serían vsif000 Verb (semiauxiliary, indicative, future) será, seremos vsii000 Verb (semiauxiliary, indicative, imperfect) era, éramos vsip000 Verb (semiauxiliary, indicative, present) es, son vsis000 Verb (semiauxiliary, indicative, preterite) fue, fuiste vsm0000 Verb (semiauxiliary, imperative) sea, sé vsn0000 Verb (semiauxiliary, infinitive) ser vsp0000 Verb (semiauxiliary, participle) sido vssf000 Verb (semiauxiliary, subjunctive, future) fuere vssi000 Verb (semiauxiliary, subjunctive, imperfect) fuera, fuese, fuéramos vssp000 Verb (semiauxiliary, subjunctive, present) sea, seamos Dates w Date octubre, jueves, 2002 Numerals z0 Numeral 547.000, 04, 52,52 zm Numeral qualifier (currency) dólares, euros zu Numeral qualifier (other units) km, cc Other word Emoticon or other symbol :), ® What phrasal category set does the parser use?
The phrasal category set is a superset of the categories used in the AnCora corpus (see the first column of their syntactic annotation documentation). We have added several grup.* constituents in order to group together newly split tokens after multi-word expression expansion (detailed above). The 29 total phrasal categories are listed below. We give examples (with spans of the phrasal constituents bolded) in the third column.
Name Description Examples conj Conjunction No obstante, en el mercado …
la fauna y la floragerundi Gerund responder atacando grup.a Adjective group grup.adv Adverb group grup.cc * Coordinating conjunction group sino que lo pongo grup.cs * Subordinating conjunction group mientras que el Ibex … grup.nom Noun group un foro en Internet recogerá …
permitieron a los mercados bursátiles europeos dar …grup.prep * Preposition group a partir de hoy
están por encima de los demásgrup.pron * Pronoun group El mío está … grup.verb Verb group Francfort perdió el 0,05%
las voces empiezan a subir de tonogrup.w * Date group en el pleno del pasado viernes
desde el 19 de mayo por …grup.z * Numeral group el 2,85 % inc Inserted element El Gobierno , apuntó Pimentel, se …
Testimoni silenciós (foto derecha)infinitiu Infinitive permitiría regular actividades …
para no empezar a regalar un tiempointerjeccio Interjection Ojalá Aznar
Bueno, hay una …morfema.pronominal Pronominal morpheme él se reafirmó
a oírse1 con más frecuenciamorfema.verbal Verbal morpheme se habla español neg Negation no sabía exactamente participi Participle espléndidamente decorada prep Preposition la sostuvo con cuidado relatiu Relative pronoun (complementizer) lo que iba a hacer ROOT Sentence root S Clause lo que iba a hacer s.a Adjective phrase un hermoso trabajo sadv Adverbial phrase Al2 final se realizó …
se comprometió anochesentence Main sentence sn Noun phrase En este sentido …
por lo que asegurósp Prepositional phrase … decisión tomada por las autoridades spec Specifier el término
todos los objetivosFootnotes
* These constituents do not appear in the original AnCora corpus.
1 Recall that clitic pronouns are treated as separate tokens in our modified corpus.
2 This is tokenized as A el in our modified corpus.
How well do the parsers work?
Is there a Spanish dependency parser?
Yes.Where does the Spanish-specific source code live?
The majority of the code for dealing with Spanish in particular lives in the package edu.stanford.nlp.international.spanish. Note that this package is a mix of (a) code which works with Spanish in general and (b) code which works specifically with the AnCora corpus. The purpose of a particular class is stated in the source code comments.
Code for reading, transforming and creating new Spanish parse trees is in a separate package edu.stanford.nlp.trees.international.spanish.
You can activate the Spanish pipeline using a special properties file StanfordCoreNLP-spanish.properties, shipped in the Spanish models jar. Here's how to run the default pipeline with some file test.txt:
$ java -cp stanford-corenlp-3.5.2.jar:stanford-spanish-corenlp-2015-01-08-models.jar edu.stanford.nlp.pipeline.StanfordCoreNLP -properties StanfordCoreNLP-spanish.properties -file test.txt
Adding annotator tokenize
Adding annotator ssplit
Adding annotator pos
Reading POS tagger model from edu/stanford/nlp/models/pos-tagger/spanish/spanish-distsim.tagger ... done [0.8 sec].
Adding annotator ner
Loading classifier from edu/stanford/nlp/models/ner/spanish.ancora.distsim.s512.crf.ser.gz ... done [2.4 sec].
Adding annotator parse
Loading parser from serialized file edu/stanford/nlp/models/lexparser/spanishPCFG.ser.gz ...
Initializing lexicon scores ... The 19 open class tags are: [ nc0s000 np00000 vmis000 rg nc0p000 vmsp000 vmn0000 vmip000 aq0000 aq0000-part vmp0000 vmg0000 z0 w vmif000 nc00000 vmii000 vmic000 vmsi000 ]
done [0.6 sec].
Ready to process: 1 files, skipped 0, total 1
Processing file test.txt ... writing to test.txt.xml {
Annotating file test.txt [0.305 seconds]
} [0.351 seconds]
Processed 1 documents
Skipped 0 documents, error annotating 0 documents
Annotation pipeline timing information:
TokenizerAnnotator: 0.2 sec.
WordsToSentencesAnnotator: 0.0 sec.
POSTaggerAnnotator: 0.0 sec.
NERCombinerAnnotator: 0.0 sec.
ParserAnnotator: 0.1 sec.
TOTAL: 0.3 sec. for 8 tokens at 26.5 tokens/sec.
Pipeline setup: 0.0 sec.
Total time for StanfordCoreNLP pipeline: 0.4 sec.
For general questions, see also the
Parser FAQ. Please send any other
questions or feedback, or extensions and bugfixes to
parser-user@lists.stanford.edu
or
parser-support@lists.stanford.edu.