Thanks for reading our paper and visiting this project page! If you have any questions, feel free to email us.
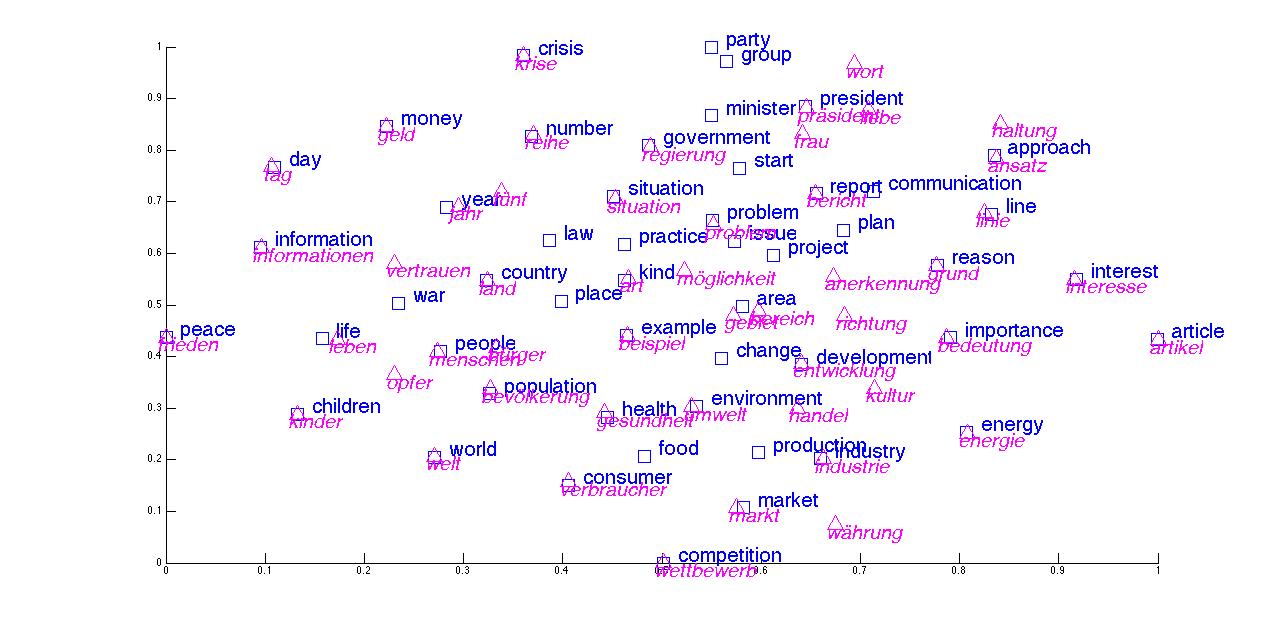
Data: We release a counter part of the Wordsim 353 dataset in German here.
Bilingual Embeddings:
Our trained bilingual embeddings whose performances are reported in the paper can be found below:
Using unsupervised alignments learned by Berkeley Aligner:
[unsup.40.en]
[unsup.40.de]
[unsup.128.en]
[unsup.128.de]
[unsup.256.en]
[unsup.256.de]
[unsup.512.en]
[unsup.512.de]
.
Using monotonic alignment assumption:
[mono.40.en]
[mono.40.de]
[mono.128.en]
[mono.128.de]
.
Code: The code is available on github.
Description: The bivec code was originated from Tomas Mikolov's word2vec. It trains bilingual embeddings as described in our paper. Besides, it has all the functionalities of word2vec with added features and code clarity.
Features: (a) Train bilingual embeddings as described in our NAACL 2015 workshop paper. (b) When training bilingual embeddings for English and German, it automatically produces the cross-lingual document classification results. (c) For monolingual embeddings, the code outputs word similarity results for English, German and word analogy results for English. (d) Save output vectors besides input vectors. (e) Automatically save vocab file and load vocab (if there's one exists). (f) The code has been extensively refactored to make it easier to understand and more comments have been added.
References: (a) https://code.google.com/p/word2vec/.
Citation: