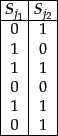The simplest approach to detecting duplicates is to compute, for each web page, a fingerprint that is a succinct (say 64-bit) digest of the characters on that page. Then, whenever the fingerprints of two web pages are equal, we test whether the pages themselves are equal and if so declare one of them to be a duplicate copy of the other. This simplistic approach fails to capture a crucial and widespread phenomenon on the Web: near duplication. In many cases, the contents of one web page are identical to those of another except for a few characters - say, a notation showing the date and time at which the page was last modified. Even in such cases, we want to be able to declare the two pages to be close enough that we only index one copy. Short of exhaustively comparing all pairs of web pages, an infeasible task at the scale of billions of pages, how can we detect and filter out such near duplicates?
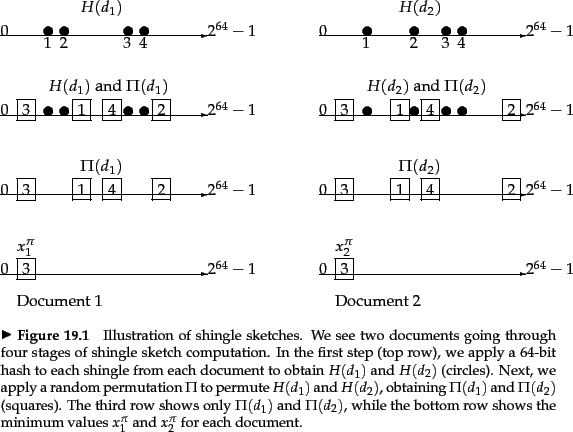
We now describe a solution to the problem of detecting near-duplicate web pages. The answer lies in a technique known as shingling . Given a positive integer ![]() and a sequence of terms in a document
and a sequence of terms in a document ![]() , define the
, define the ![]() -shingles of
-shingles of ![]() to be the set of all consecutive sequences of
to be the set of all consecutive sequences of ![]() terms in
terms in ![]() . As an example, consider the following text: a rose is a rose is a rose. The 4-shingles for this text (
. As an example, consider the following text: a rose is a rose is a rose. The 4-shingles for this text (![]() is a typical value used in the detection of near-duplicate web pages) are a rose is a, rose is a rose and is a rose is. The first two of these shingles each occur twice in the text. Intuitively, two documents are near duplicates if the sets of shingles generated from them are nearly the same. We now make this intuition precise, then develop a method for efficiently computing and comparing the sets of shingles for all web pages.
is a typical value used in the detection of near-duplicate web pages) are a rose is a, rose is a rose and is a rose is. The first two of these shingles each occur twice in the text. Intuitively, two documents are near duplicates if the sets of shingles generated from them are nearly the same. We now make this intuition precise, then develop a method for efficiently computing and comparing the sets of shingles for all web pages.
Let ![]() denote the set of shingles of document
denote the set of shingles of document ![]() .
Recall the Jaccard coefficient from page 3.3.4 , which measures the degree of overlap
between the sets
.
Recall the Jaccard coefficient from page 3.3.4 , which measures the degree of overlap
between the sets ![]() and
and ![]() as
as
![]() ; denote this by
; denote this by
![]() . Our test for near duplication between
. Our test for near duplication between ![]() and
and ![]() is to compute this Jaccard coefficient; if it exceeds a preset threshold (say,
is to compute this Jaccard coefficient; if it exceeds a preset threshold (say, ![]() ), we declare them near duplicates and eliminate one from indexing. However, this does not appear to have simplified matters: we still have to compute Jaccard coefficients pairwise.
), we declare them near duplicates and eliminate one from indexing. However, this does not appear to have simplified matters: we still have to compute Jaccard coefficients pairwise.
To avoid this, we use a form of hashing. First, we map every shingle into a hash value over a large space, say 64 bits. For ![]() , let
, let ![]() be the corresponding set of 64-bit hash values derived from
be the corresponding set of 64-bit hash values derived from ![]() . We now invoke the following trick to detect document pairs whose sets
. We now invoke the following trick to detect document pairs whose sets ![]() have large Jaccard overlaps. Let
have large Jaccard overlaps. Let ![]() be a random permutation from the 64-bit integers to the 64-bit integers. Denote by
be a random permutation from the 64-bit integers to the 64-bit integers. Denote by ![]() the set of permuted hash values in
the set of permuted hash values in ![]() ; thus for each
; thus for each ![]() , there is a corresponding value
, there is a corresponding value
![]() .
.
Let ![]() be the smallest integer in
be the smallest integer in ![]() . Then
. Then
| (247) |
Proof.
We give the proof in a slightly more general setting: consider a family of sets whose elements are drawn from a common universe. View the sets as columns of a matrix ![]() , with one row for each element in the universe. The element
, with one row for each element in the universe. The element ![]() if element
if element ![]() is present in the set
is present in the set ![]() that the
that the ![]() th column represents.
th column represents.
Let ![]() be a random permutation of the rows of
be a random permutation of the rows of ![]() ; denote by
; denote by ![]() the column that results from applying
the column that results from applying ![]() to the
to the ![]() th column. Finally, let
th column. Finally, let ![]() be the index of the first row in which the column
be the index of the first row in which the column ![]() has a
has a ![]() . We then prove that for any two columns
. We then prove that for any two columns ![]() ,
,
| (248) |
Consider two columns ![]() as shown in Figure 19.9 .
The ordered pairs of entries of
as shown in Figure 19.9 .
The ordered pairs of entries of ![]() and
and ![]() partition the rows into four types: those with 0's in both of these columns, those with a 0 in
partition the rows into four types: those with 0's in both of these columns, those with a 0 in ![]() and a 1 in
and a 1 in ![]() , those with a 1 in
, those with a 1 in ![]() and a 0 in
and a 0 in ![]() , and finally those with 1's in both of these columns. Indeed, the first four rows of Figure 19.9 exemplify all of these four types of rows. Denote by
, and finally those with 1's in both of these columns. Indeed, the first four rows of Figure 19.9 exemplify all of these four types of rows. Denote by ![]() the number of rows with 0's in both columns,
the number of rows with 0's in both columns, ![]() the second,
the second, ![]() the third and
the third and ![]() the fourth. Then,
the fourth. Then,
Thus, our test for the Jaccard coefficient of the shingle sets is probabilistic: we compare the computed values ![]() from different documents. If a pair coincides, we have candidate near duplicates. Repeat the process independently for 200 random permutations
from different documents. If a pair coincides, we have candidate near duplicates. Repeat the process independently for 200 random permutations ![]() (a choice suggested in the literature). Call the set of the 200 resulting values of
(a choice suggested in the literature). Call the set of the 200 resulting values of ![]() the sketch
the sketch ![]() of
of ![]() . We can then estimate the Jaccard coefficient for any pair of documents
. We can then estimate the Jaccard coefficient for any pair of documents ![]() to be
to be
![]() ; if this exceeds a preset threshold, we declare that
; if this exceeds a preset threshold, we declare that ![]() and
and ![]() are similar.
are similar.
How can we quickly compute
![]() for all
pairs
for all
pairs ![]() ? Indeed, how do we represent all pairs of
documents that are similar, without incurring a blowup that
is quadratic in the number of documents? First, we use
fingerprints to remove all but one copy of identical
documents. We may also remove common HTML tags and integers
from the shingle computation, to eliminate shingles that
occur very commonly in documents without telling us anything
about duplication. Next we use a
union-find algorithm to create clusters that contain documents that are similar. To do this, we must accomplish a crucial step: going from the set of sketches to the set of pairs
? Indeed, how do we represent all pairs of
documents that are similar, without incurring a blowup that
is quadratic in the number of documents? First, we use
fingerprints to remove all but one copy of identical
documents. We may also remove common HTML tags and integers
from the shingle computation, to eliminate shingles that
occur very commonly in documents without telling us anything
about duplication. Next we use a
union-find algorithm to create clusters that contain documents that are similar. To do this, we must accomplish a crucial step: going from the set of sketches to the set of pairs ![]() such that
such that ![]() and
and ![]() are similar.
are similar.
To this end, we compute the number of shingles in common for any pair of documents whose sketches have any members in common. We begin with the list
![]() sorted by
sorted by ![]() pairs. For each
pairs. For each ![]() , we can now generate all pairs
, we can now generate all pairs ![]() for which
for which ![]() is present in both their sketches. From these we can compute, for each pair
is present in both their sketches. From these we can compute, for each pair ![]() with non-zero sketch overlap, a count of the number of
with non-zero sketch overlap, a count of the number of ![]() values they have in common. By applying a preset threshold, we know which pairs
values they have in common. By applying a preset threshold, we know which pairs ![]() have heavily overlapping sketches. For instance, if the threshold were 80%, we would need the count to be at least 160 for any
have heavily overlapping sketches. For instance, if the threshold were 80%, we would need the count to be at least 160 for any ![]() . As we identify such pairs, we run the union-find to group documents into near-duplicate ``syntactic clusters''. This is essentially a variant of the single-link clustering algorithm introduced in Section 17.2 (page
. As we identify such pairs, we run the union-find to group documents into near-duplicate ``syntactic clusters''. This is essentially a variant of the single-link clustering algorithm introduced in Section 17.2 (page ![]() ).
).
One final trick cuts down the space needed in the computation of
![]() for pairs
for pairs ![]() , which in principle could still demand space quadratic in the number of documents. To remove from consideration those pairs
, which in principle could still demand space quadratic in the number of documents. To remove from consideration those pairs ![]() whose sketches have few shingles in common, we preprocess the sketch for each document as follows: sort the
whose sketches have few shingles in common, we preprocess the sketch for each document as follows: sort the ![]() in the sketch, then shingle this sorted sequence to generate a set of super-shingles for each document. If two documents have a super-shingle in common, we proceed to compute the precise value of
in the sketch, then shingle this sorted sequence to generate a set of super-shingles for each document. If two documents have a super-shingle in common, we proceed to compute the precise value of
![]() . This again is a heuristic but can be highly effective in cutting down the number of
. This again is a heuristic but can be highly effective in cutting down the number of ![]() pairs for which we accumulate the sketch overlap counts.
pairs for which we accumulate the sketch overlap counts.
Exercises.