Stanford Dependencies
Universal Dependencies | Download | About | Ongoing projects | SD for English | SD for Chinese | Other languages | Other parsers | Mailing lists | GUI
Starting in 2005, we developed a linguistically sound, surface-syntax oriented dependency representation for English, which came to be known as Stanford Dependencies. This representation was met with interest by many people and later in 2013 we began collaborating with a broader consortium to propose Universal Dependencies, a similar dependency representation suitable for all languages.
Universal Dependencies
Since version 3.5.2 the Stanford Parser and Stanford CoreNLP output grammatical relations in the Universal Dependencies v1 representation by default. Take a look at the Universal Dependencies v1 documentation for a detailed description of the v1 representation, its set of relations, and links to dependency treebank downloads. You might also want to look at the the current (v2) Universal Dependencies documentation, but we have yet to update our tools to this representation. More information on the Universal Dependencies converter and the enhanced representation can be found in this paper.
If you have an English constituency treebank in Penn Treebank (s-expression) format in the file or directory treebank, you can use our code to convert it to a file of basic Universal Dependencies in CoNLL-U format with this command:
java -mx1g edu.stanford.nlp.trees.ud.UniversalDependenciesConverter -treeFile treebank > treebank.conllu
Stanford Dependencies
We also still support the original Stanford Dependencies representation as described on this page and in the original papers. To output relations in the original Stanford Dependencies representation use the -originalDependencies option when running the parser or the -parse.originalDependencies option when running a CoreNLP pipeline with the PCFG parser. If you are using the Neural Network dependency parser and want to get the original Stanford Dependencies, you have to use the model trained on a corpus annotated with the Stanford Dependencies representation using the following option:
-depparse.model "edu/stanford/nlp/models/parser/nndep/english_SD.gz"
Download
The dependency code is part of the Stanford parser. Go here to download a version.
About
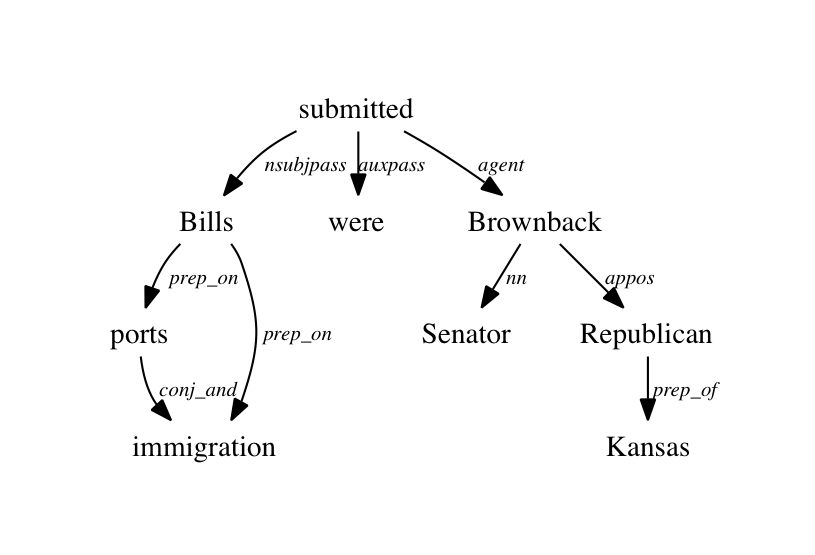
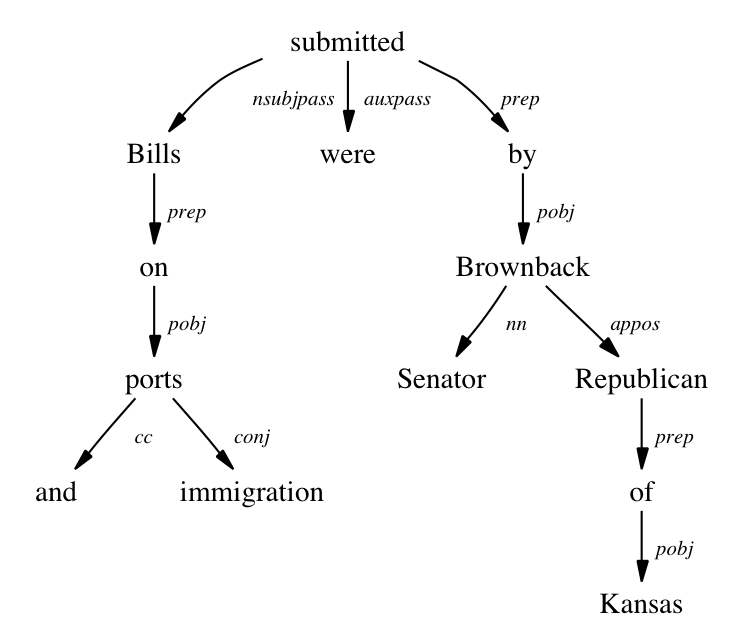
Stanford dependencies provides a representation of grammatical relations between words in a sentence. They have been designed to be easily understood and effectively used by people who want to extract textual relations. Stanford dependencies (SD) are triplets: name of the relation, governor and dependent. The standard dependencies for the sentence Bills on ports and immigration were submitted by Senator Brownback, Republican of Kansas are given below, as well as two graphical representations: the standard dependencies (collapsed and propagated) and the basic dependency representation in which each word in the sentence (except the head of the sentence) is the dependent of one other word (no collapsing, no propagation).
| Dependencies for Bills on ports and immigration were submitted by Senator Brownback, Republican of Kansas | Figure 1. Standard Stanford dependencies (collapsed and propagated) | Figure 2. Basic dependencies |
|---|---|---|
|
nsubjpass(submitted, Bills) auxpass(submitted, were) agent(submitted, Brownback) nn(Brownback, Senator) appos(Brownback, Republican) prep_of(Republican, Kansas) prep_on(Bills, ports) conj_and(ports, immigration) prep_on(Bills, immigration) |
 |
 |
Ongoing projects
We created a gold standard dependency corpus on top of the English Web Treebank (LDC2012T13). We manually annotated 254,830 words with SD for English. The effort is meant to address the scarcity of both gold standard dependency corpora for English and annotated resources for parsing web test. This resource is described here:
Natalia Silveira, Timothy Dozat, Marie-Catherine de Marneffe, Samuel R. Bowman, Miriam Connor, John Bauer and Christopher D. Manning. 2014. A Gold Standard Dependency Corpus for English. In LREC 2014.
This annotation effort has led to refinements of Stanford Dependencies. We describe changes to the standard and propose analyses for a few syntactic constructions of interest, to be found in the following paper:
Marie-Catherine de Marneffe, Miriam Connor, Natalia Silveira, Samuel R. Bowman, Timothy Dozat and Christopher D. Manning. 2013. More constructions, more genres: Extending Stanford Dependencies. In DepLing 2013.
We are now primarily working on an improved taxonomy to capture grammatical relations across languages, including morphologically rich ones. A first version of this new standard, called Universal Dependencies, is described here:
Marie-Catherine de Marneffe, Natalia Silveira, Timothy Dozat, Katri Haverinen, Filip Ginter, Joakim Nivre, and Christopher D. Manning. 2014. Universal Stanford Dependencies: A cross-linguistic typology. In LREC 2014.
A more recent version of Universal Dependencies is described in the following two papers:
Joakim Nivre, Marie-Catherine de Marneffe, Filip Ginter, Yoav Goldberg, Jan Hajič, Christopher D. Manning, Ryan McDonald, Slav Petrov, Sampo Pyysalo, Natalia Silveira, Reut Tsarfaty, and Daniel Zeman. 2016. Universal Dependencies v1: A Multilingual Treebank Collection. In LREC 2016.
Sebastian Schuster and Christopher D. Manning. 2016. Enhanced English Universal Dependencies: An Improved Representation for Natural Language Understanding Tasks. In LREC 2016.
The most up to date version of Universal Depencies is documented online at http://www.universaldependencies.org.
SD for English
The English version of the Stanford dependencies has been developed by Marie-Catherine de Marneffe, Bill MacCartney, and Christopher Manning. All details about the English dependencies can be found in the manual:
Marie-Catherine de Marneffe and Christopher D. Manning. 2008. Stanford Dependencies manual.The manual contains a description of all the existing English grammatical relations in the representation. It explains the differences between the five types of representation available, and how such types of representation can be obtained. It also gives references to further discussion and use of the Stanford dependencies. The dependencies are produced using hand-written
tregex patterns over phrase-structure trees as described in:
Marie-Catherine de Marneffe, Bill MacCartney and Christopher D. Manning. 2006. Generating Typed Dependency Parses from Phrase Structure Parses. In LREC 2006.The main ideas motivating the Stanford dependency representation appear in this paper:
Marie-Catherine de Marneffe and Christopher D. Manning. 2008. The Stanford typed dependencies representation. In COLING 2008 Workshop on Cross-framework and Cross-domain Parser Evaluation.
The definition of the set of dependencies has evolved a little over the years, and the particular patterns used to convert phrase structure trees to dependencies have been improved quite a bit. Hence, if you are publishing a paper using Stanford Dependencies, we really appreciate it if you could indicate precisely which version you are using. This is easily done by citing the version of the Stanford Parser code used.
In practice, the dependencies can be obtained using our software in two ways. Either by using the Stanford parser with the -outputFormat typedDependencies option on raw text, or directly on phrase-structure trees using the EnglishGrammaticalStructure class available in the parser package.
If you have an English constituency treebank in Penn Treebank (s-expression) format in the file or directory treebank, you can use our code to convert it to a file of basic Stanford Dependencies in CoNLL-X format with this command:
java -mx1g edu.stanford.nlp.trees.EnglishGrammaticalStructure -basic -keepPunct -conllx -treeFile treebank > treebank.sd
For English, five different variants of the dependencies are available, and different options can be used to get these. The default representation is the "CCprocessed" one, which collapses and propagates dependencies (as shown in Figure 1, in contrast to Figure 2, which shows the "basic" dependencies, which are not collapsed nor propagated). For more details, refer to section 5 of the Stanford Dependencies manual.
Here are some examples of Stanford Dependencies representations of sentences, originating from the Coling 2008 Workshop on Cross-Framework and Cross-Domain Parser Evaluation: required-wsj02.Stanford, optional-wsj02.Stanford, genia.stanford. Only the required WSJ set were hand-verified; the representations in the other two sets were automatically generated.
A corpus of English biomedical texts, with hand-corrected annotations in a slight variant of the Stanford typed dependency format is available from The BioInfer project.
SD for Chinese
Stanford dependencies are also available for Chinese. The Chinese dependencies have been developed by Huihsin Tseng and Pi-Chuan Chang. A brief description of the Chinese grammatical relations can be found in this paper.
If you have a version of the LDC Chinese Treebank (or some other Chinese constituency treebank in Penn Treebank s-expression format) in the file or directorytreebank, you can use our code to convert it to a file of basic Chinse Stanford Dependencies in CoNLL-X format with this command:
java -mx1g edu.stanford.nlp.trees.international.pennchinese.ChineseGrammaticalStructure -basic -keepPunct -conllx -treeFile treebank > treebank.csd
Other Languages
Versions of Stanford Dependencies have also been developed by outside groups for a number of other languages. Two prominent examples are Finnish (the Turku Dependency Treebank) and Persian (the Uppsala Persian Dependency Treebank). There is now a multi-site effort to produce dependency treebanks over a broad range of languages adopting a compatible dependency taxonomy. More details about this Universal Dependency Treebank can be found in the LREC 2014 and LREC 2016 papers mentioned above, in the current treebank release, and in new documentation.
Other parsers
While the original and canonical approach to generating the Stanford
Dependencies is using the Stanford parser, there are now many other
parsers which produce them, which may offer better speed or precision.
Any phrase structure parser that constructs PTB style trees can be used,
in addition to any trainable dependency parser. When using an
alternative phrase structure parser, the Stanford Parser
class EnglishGrammaticalStructure is used to extract
dependencies from the resulting constituent parse trees. Trainable
dependency parsers can produce the basic Stanford Dependency
representation. This is a projective variant of the Stanford
Dependencies that can be transformed into the default representation,
CCprocessed, using EnglishGrammaticalStructure.
The table below summarizes some methods for generating the Stanford
Dependencies along with the speed and accuracy of each approach on
section 22 of the Penn TreeBank. Links are provided to the corresponding
software packages and trained parsing models (some of the dependency
models were trained by us). All the accuracies and timings here are for
SDs corresponding to Stanford Parser version 1.6.2. The tree or basic
dependency output is in each case converted to CCprocessed dependencies
using our EnglishGrammaticalStructure class, and then
evaluation is on CCprocessed dependencies. (I.e., you cannot
directly compare
these numbers with results on recovering Stanford basic dependencies,
which is an easier task.)
| Approach | Labeled Attachment (F1) | Time (mm:ss) | Links | ||
|---|---|---|---|---|---|
| Constituent | |||||
| Charniak-Johnson | default (T210) | 89.1 | 11:18 | [Software] | |
| T50 | 86.7 | 3:32 | |||
| T10 | 75.7 | 2:17 | |||
| Berkeley Parser | 87.9 | 10:14 | [Software][Model] | ||
| Bikel | 85.3 | 29:57 | [Software][Model Data] | ||
| Stanford (englishPCFG) | 84.2 | 11:05 | [Software] | ||
| Dependency | |||||
| Ensemble Malt | 82.4 | 1:56 | [Software][Model] [Paper] | ||
| MaltParser | Nivre Eager, SVM poly deg:2 | 81.1 | 3:23 | [Software][Model we built/used] [English MaltParser model] [English MaltParser] | |
| Nivre Eager, LibLinear | 76.2 | 0:16 | [Software][Model we built/used] [English MaltParser model] [English MaltParser] | ||
| MSTParser (Eisner) | 78.8 | 6:01 | [Software][Model] | ||
| RelEx | 48.1 | 31:38 | [Software] | ||
| Easy-First Parser | [Software] | ||||
The Charniak-Johnson parser includes a model for parsing English. The Bikel parser requires users to train their own model, which can be done using the included train-from-observed utility and the model data linked above. The RelEx package is rule-based and provides a Stanford Dependency compatibility mode.
For the dependency parsers, part-of-speech (POS) tags were generated using the Stanford POS tagger and the included left3words-wsj-0-18 model. Times represent the total time required to produce the dependencies including: POS tagging (if applicable), parsing, and extraction of the CCprocessed Stanford Dependency representation. Benchmarking was done on a dual CPU Intel Xeon E5520. Multithreading was disabled for the Charniak-Johnson parser, in order to obtain a per CPU-core estimate of parsing speed.
In general, all parsers were run in their default out-of-the-box configurations. But, in addition, for the Charniak-Johnson parser, the table above also shows the speed and accuracy trade-offs from varying the amount of search by setting different T values (by default T = 210). The Charniak-Johnson parser allows users to trade off parsing accuracy for speed by adjusting how liberal the system is about expanding edges after the best-first-search has found one complete parse of the sentence: they constrain themselves to only examine Tval/10 times more edges in search of a better parse.
For more information about these parsing accuracy vs. speed trade-offs when generating Stanford Dependencies, see:
Daniel Cer, Marie-Catherine de Marneffe, Daniel Jurafsky, and Christopher D. Manning. 2010. Parsing to Stanford Dependencies: Trade-offs between speed and accuracy. In 7th International Conference on Language Resources and Evaluation (LREC 2010). [pdf, bib]
Mailing lists
To ask questions about the dependencies, you can use the same lists as for the parser, each @lists.stanford.edu:
parser-userThis is the best list to post to in order to ask questions, make announcements, or for discussion among parser users. Join the list via this webpage or by emailingparser-user-join@lists.stanford.edu. (Leave the subject and message body empty.) You can also look at the list archives.parser-announceThis list will be used only to announce new parser versions. So it will be very low volume (expect 1-3 message a year). Join the list via this webpage or by emailingparser-announce-join@lists.stanford.edu. (Leave the subject and message body empty.)parser-supportThis list goes only to the parser maintainers. It's a good address for licensing questions, etc. For general use and support questions, you're better off joining and usingparser-user. You cannot joinparser-support, but you can mail questions toparser-support@lists.stanford.edu.
GUI
Bernard Bou developed a GUI focusing on the typed dependencies, including an editor:
GrammarScope: Stanford parser grammatical relation browser
We now have a nice visualization of Stanford Dependencies in our online Stanford CoreNLP demo, provided by brat.