|
|
The Stanford Natural Language Processing Group home · people · teaching · research · publications · software · events · local |
|
|
The Stanford Natural Language Processing Group home · people · teaching · research · publications · software · events · local |
![Printer Icon [www.famfamfam.com]](printer.png) Print-friendly version
Screen version
Version 0.2.1
Print-friendly version
Screen version
Version 0.2.1
Upgrading from 0.1.x? Make sure to update your scripts to match the examples on this page. Some small changes are not backwards compatible with previous versions.
The Stanford Topic Modeling Toolbox (TMT) brings topic modeling tools to social scientists and others who wish to perform analysis on datasets that have a substantial textual component. The toolbox features that ability to:

The Stanford Topic Modeling Toolbox was written at the Stanford NLP group by:
Daniel Ramage and Evan Rosen, first released in September 2009.



Programmers: See the API Reference and the source code.
This section contains software installation instructions and the overviews the basic mechanics of running the toolbox.
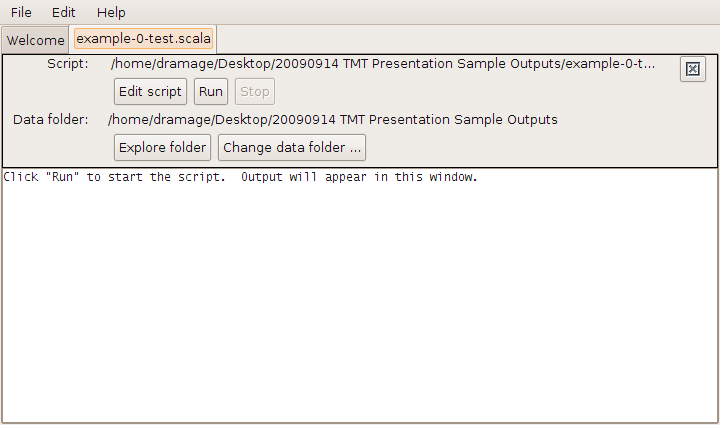
More ...java -jar tmt-0.2.1.jarexample-0-test.scala
// TMT Example 0 - Basic data loading import scalanlp.stage.source._; val pubmed = CSVFile("pubmed-oa-subset.csv"); println("Success: " + pubmed + " contains " + pubmed.data.size + " records");
This is a simple script that just loads the records contained in the sample data file pubmed-oa-subset, an subset of the Open Access database of publications in Pubmed.
Now run the toolbox as before and select "Open script ..." from the file menu. Navigate to example-0-test.scala and click open, then run.
Alternatively, you can run the script from the command line:
java -jar tmt-0.2.1.jar example-0-test.scala
If all goes well you should see the following lines of output:
Success: CSVFile("pubmed-oa-subset.csv") contains 1550 records
You're all set to continue with the tutorial. For the rest of the tutorial, invoke the toolbox in the same way as we do above but with a different script name.
[close section]The first step in using the Topic Modeling Toolbox on a data file (CSV or TSV, e.g. as exported by Excel) is to tell the toolbox where to find the text in the file. This section describes how the toolbox converts a column of text from a file into a sequence of words.
More ...The code for this example is in example-1-dataset.scala.
The process of extracting and preparing text from a CSV file can be thought of as a pipeline, where a raw CSV file goes through a series of stages that ultimately result in something that can be used to train the topic model. Here is a sample pipeline for the pubmed-oa.csv data file:
// input file to read
val pubmed = CSVFile("pubmed-oa-subset.csv");
// the text field extracted and processed from the file
val text = {
pubmed ~> // read from the pubmed file
Column(3) ~> // select column three, the abstracts
CaseFolder ~> // lowercase everything
SimpleEnglishTokenizer ~> // tokenize on spaces characters
WordsAndNumbersOnlyFilter ~> // ignore non-words and non-numbers
TermCounter ~> // collect counts (needed below)
TermMinimumLengthFilter(3) ~> // take terms with >=3 characters
TermMinimumDocumentCountFilter(4) ~> // filter terms in <4 docs
TermDynamicStopListFilter(30) ~> // filter out 30 most common terms
DocumentMinimumLengthFilter(5) // take only docs with >=5 terms
}
The input data file (in the pubmed variable) is a pointer to the CSV file you downloaded earlier. pubmed is passed through a a series of stages that each transform, filter, or otherwise interact with the data.
The first step is to select fields from your CSV file that contain the text you would like to use for training the model.
If your text data is only in one column:
CSVFile("your-csv-file.csv") ~> Column(3)
The code above will load the text from column three in the CSV file.
If your text is in more than one column:
CSVFile("your-csv-file.csv") ~> Columns(2,3) ~> Join(" ")
The code above select columns two and three, and then concatenates their contents with a space character used as glue.
The next set of manipulations involves breaking up the text into its component words, a process known as tokenization. This is accomplished with:
... ~> CaseFolder ~> SimpleEnglishTokenizer ~> WordsAndNumbersOnlyFilter ~> ...
The CaseFolder is first used to make "The" and "tHE" and "THE" all look like "the" — i.e. the case folder reduces the number of distinct word types seen by the model by turning all character to lowercase.
Next, the text is tokenized using the SimpleEnglishTokenizer, which removes punctuation from the ends of words and then splits up the input text by whitespace characters (tabs, spaces, carriage returns, etc.). You could alternatively use the WhitespaceTokenizer if your text fields have already been processed into cleaned tokens.
Words that are entirely punctuation and other non-word non-number characters are removed from the generated lists of tokenized documents by using the WordsAndNumbersOnlyFilter.
LDA can be useful for extracting patterns in meaningful word use, but it is not good at determining which words are meaningful. It is often the case that the use of very common words like 'the' do not indicate the type of similarity between documents in which one is interested. Single letters or other small sequences are also rarely useful for understanding content. To lead LDA towards extracting patterns among meaningful words, we have implemented a collection of standard heuristics:
... ~> TermCounter ~>
TermMinimumLengthFilter(3) ~>
TermMinimumDocumentCountFilter(4) ~>
TermDynamicStopListFilter(30) ~> ...
The code above removes terms that are shorter than three characters (removing, e.g. words like "is"), words that appear in less than four documents (because very rare words tell us little about the similarity of documents), and 30 most common words in the corpus (because words that are ubiquitous also tell us little about the similarity of documents, they are removed and conventionally denoted "stop words"). These values might need to be updated if you are working with a much larger or much smaller corpus than a few thousand documents.
The TermCounter stage must first computes some statistics needed by the next stages. These statistics are stored in the metadata associated with each parcel, which enables any downstream stage to access that information.
DocumentMinimumLengthFilter(length) to remove all documents shorter than the specified length.
Run example 1 (example-1-dataset.scala). This program will first load the data pipeline and then print out information about the loaded text dataset, including a signature of the dataset (the "parcel") and the list of 30 stop words found for this corpus. [Note that in PubMed, "gene" is filtered out because it is so common!]
[close section]Once you've prepared a dataset to learn against, you're all set to train a topic model. This example shows how to train an instance of Latent Dirichlet Allocation using the dataset you prepared above.
More ...The code for this example is in example-2-lda-learn.scala
// input file to read
val pubmed = CSVFile("pubmed-oa-subset.csv");
// the text field extracted and processed from the file
val text = {
pubmed ~> // read from the pubmed file
Column(3) ~> // select column three, the abstracts
CaseFolder ~> // lowercase everything
SimpleEnglishTokenizer ~> // tokenize on spaces characters
WordsAndNumbersOnlyFilter ~> // ignore non-words and non-numbers
TermCounter ~> // collect counts (needed below)
TermMinimumLengthFilter(3) ~> // take terms with >=3 characters
TermMinimumDocumentCountFilter(4) ~> // filter terms in <4 docs
TermDynamicStopListFilter(30) ~> // filter out 30 most common terms
DocumentMinimumLengthFilter(5) // take only docs with >=5 terms
}
This code snippet is the same as in the previous tutorial. It extracts and prepares
the text from column 3.
// turn the text into a dataset ready to be used with LDA
val dataset = LDADataset(text);
// define the model parameters
val numTopics = 30;
val modelParams = LDA.ModelParams(numTopics);
// this is equivalent to:
//
// val modelParams = LDA.ModelParams(numTopics,
// LDA.TermSmoothing(.01),
// LDA.TopicSmoothing(50.0 / numTopics));
// define the training parameters
val trainingParams = GibbsLDATrainer.DefaultTrainingParams;
// this is equivalent to:
//
// import GibbsLDA.LearningModel._;
// val trainingParams =
// TrainingParams(MaxIterations(1500),
// SaveEvery(50, LogProbabilityEstimate,
// DocumentTopicDistributions,
// DocumentTopicAssignments));
//
// SaveEvery(...) could be replaced by SaveFinal() to write less output
//
// val trainingParams = TrainingParams(MaxIterations(1500), SaveFinal());
// Name of the output model folder to generate
val output = file("lda-"+dataset.signature+"-"+modelParams.signature);
// Trains the model: the model (and intermediate models) are written to the
// output folder. If a partially trained model with the same dataset and
// parameters exists in that folder, training will be resumed.
TrainGibbsLDA(output, dataset, modelParams, trainingParams); // renamed 0.2
// new in 0.2 - load the per-word topic assignments saved during training
// (averages across last 10 saved models)0
val perDocWordTopicProbability =
LoadTrainingPerWordTopicDistributions(output, dataset, 10);
// new in 0.2 - write per-document topic usage to file
DocumentTopicUsage(perDocWordTopicProbability) | CSVFile(output, "usage.csv");
The model will output status message as it trains. It'll take a few minutes. The last lines generate a file in the output folder that contains the per-document topic distribution of each training document. This file has the same number of rows as the original input (with empty rows for documents that were skipped during training), so it can be aligned with the original input CSV using a simple copy and paste.
The generated model output folder, in this case lda-f7a35bfa-30-2b517070-7c1f94d2, contains everything needed to analyze the learning process and to load the model back in from disk.
| dataset.txt | The history of stages used to get the text used for training. |
| model-params.txt | The model parameters specified during training. |
| training-params.txt | The training parameters used to determine convergence. |
| 00000 - 01500 | napshots of the model during training every 50 iterations. |
A simple way to see if the training procedure on the model has converged is to look at the values in the numbered folders of log-probability-estimate.txt. This file contains an informal estimate of the model's estimation of the probability of the data while training. The numbers tend to make a curve that tapers off but never stops changing completely. If the numbers don't look like they've stabilized, you might want to retrain using a higher number of iterations. If you re-run the script with a higher number of iterations (or if continue training a model that was interrupted during traiing), the toolbox will continue training the model from the highest iteration stored on disk.
This tutorial describes how to select model parameters such as the number of topics by a (computationally intensive) tuning procedure, which searches for the parameters that minimize the model's perplexity on held-out data.
More ...The code for this example is in example-4-lda-select.scala
The script splits a document into two subsets: one used for training models, the other used for evaluating their perplexity on unseen data. Perplexity is scored on the evaluation documents by first splitting each document in half. The per-document topic distribution is estimated on the first half of the words. The toolbox then computes an average of how surprised it was by the words in the second half of the document, where surprise is measured in the number of equiprobable word choices, on average. The value is written into each trained model's output folder as perplexity.txt, with lower numbers meaning a surer model.
The perplexity scores are not comparable across corpora because they will be affected by different vocabulary size. However, they can be used to compare models trained on the same data (as in the example script). However, be aware that models with better perplexity scores don't always produce more interpretable topics or topics better suited to a particular task. Perplexity scores can be used as stable measures for picking among alternatives, for lack of a better option.
Some non-parametric topic models can automatically select the number of topics as part of the model training procedure itself. However, these models (such as the Hierarchical Dirichlet Process) are not yet implemented in the toolbox. Even in such models, some parameters remain to be tuned, such as the topic smoothing and term smoothing parameters.
This tutorial shows how to generate basic outputs by querying the topic model for information about topic and word usage in various subsets of the data.
More ...The code for this example is in example-3-lda-infer.scala
// input file to read
val pubmed = CSVFile("pubmed-oa-subset.csv");
// the text field extracted and processed from the file
val text = {
pubmed ~> // read from the pubmed file
Column(3) ~> // select column three, the abstracts
CaseFolder ~> // lowercase everything
SimpleEnglishTokenizer ~> // tokenize on spaces characters
WordsAndNumbersOnlyFilter ~> // ignore non-words and non-numbers
TermCounter ~> // collect counts (needed below)
TermMinimumLengthFilter(3) ~> // take terms with >=3 characters
TermMinimumDocumentCountFilter(4) ~> // filter terms in <4 docs
TermDynamicStopListFilter(30) ~> // filter out 30 most common terms
DocumentMinimumLengthFilter(5) // take only docs with >=5 terms
}
// turn the text into a dataset ready to be used with LDA
val dataset = LDADataset(text);
// the path to the model we want to load
val modelPath = file("lda-f7a35bfa-30-2b517070-7c1f94d2");
// load the trained model
val model = LoadGibbsLDA(modelPath);
// infer topic distributions for each word in each document in the dataset.
System.err.println("Running inference ... (this could take several minutes)");
val perDocWordTopicProbability = InferPerWordTopicDistributions(model, dataset);
Our implementation currently supports three primary queries on the product of inference.
//
// now build an object to query the inferred outputs
//
System.err.println("Generating general outputs ...");
// build an object to query the model
val fullLDAQuery = LDAQuery(perDocWordTopicProbability);
// write the top 20 words per topic to a csv file
fullLDAQuery.topK(20) | CSVFile("pubmed-topk.csv");
// track some words' usage
fullLDAQuery.trackWords("gene","probability") | CSVFile("pubmed-words.csv");
// write the overall topic usage
fullLDAQuery.usage | CSVFile("pubmed-usage.csv");
The statistic generated is (fractional) documents - i.e. how many documents were assigned to the given topic.
Often, more data is associated with each document than just its words. In our example, we also have a year associated with each document. We can query by "slices" of the dataset, which subdivide the counts as generated above by metadata listed in the grouping information of each document.
//
// now build an object to query by a field
//
System.err.println("Generating sliced outputs ...");
// define fields from the dataset we are going to slice against
val year = pubmed ~> Column(1); // select column 1, the year
// create a slice object by binding the output of inference with the fields
val sliceLDAQuery = SlicedLDAQuery(perDocWordTopicProbability, year);
sliceLDAQuery.topK(20) | CSVFile("pubmed-slice-topk.csv");
sliceLDAQuery.trackWords("gene","probability") | CSVFile("pubmed-slice-trackwords.csv");
sliceLDAQuery.usage | CSVFile("pubmed-slice-usage.csv");
The next tutorial shows you what you can do with these outputs in more detail.
[close section]The CSV files generated in the previous tutorial can be directly imported into Excel to provide an advanced analysis and plotting platform for understanding, plotting, and manipulating the topic model outputs. If things don't seem to make sense, you might need to try different model parameters.
Note that the screenshots below were based on the output generated in version 0.1.2. As of 0.2, each generated output file has a header line and possibly a few more informative fields.





Labeled LDA is a supervised topic model for credit attribution in multi-labeled corpora [pdf, bib]. If one of the columns in your input text file contains labels or tags that apply to the document, you can use Labeled LDA to discover which parts of each document go with each label, and to learn accurate models of the words best associated with each label globally.
More ...The code for this example is in example-5-labeled-lda-learn.scala
This example is very similar to the example on training a regular LDA model, except for a few small changes. One is that instead of specifying LDA.ModelParams, we specify LabeledLDA.ModelParams, which doesn't include an option for a number of topics because the topics are assumed to be in one-to-one alignment with the label set (although this assumption is conceptually easy to relax).
To specify a LabeledLDA dataset, we need to tell the toolbox where the text comes from as well as where the labels come from.
// the text field extracted and processed from the file
val text = {
pubmed ~> // read from the pubmed file
Column(3) ~> // select column three, the abstracts
CaseFolder ~> // lowercase everything
SimpleEnglishTokenizer ~> // tokenize on spaces characters
WordsAndNumbersOnlyFilter ~> // ignore non-words and non-numbers
TermCounter ~> // collect counts (needed below)
TermMinimumLengthFilter(3) ~> // take terms with >=3 characters
TermMinimumDocumentCountFilter(4) ~> // filter terms in <4 docs
TermDynamicStopListFilter(30) ~> // filter out 30 most common terms
DocumentMinimumLengthFilter(5) // take only docs with >=5 terms
}
// define fields from the dataset we are going to slice against
val year = {
pubmed ~> // read from the pubmed file
Column(1) ~> // take column one, the year
WhitespaceTokenizer // turns label field into an array
}
val dataset = LabeledLDADataset(text, year);
Labeled LDA assumes that each document can use only topics that are named in the label set. Here each document participates in only one label (its year). Years are not particularly interesting labels (versus, say, a field that contained multiple tags describing each paper), but it suffices for this example. This example will eventually be to something based on tagged web pages, but the example above demonstrates the main point for now.
Training a GibbsLabeledLDA model is similar to training a GibbsLDA model.
// Trains the model: the model (and intermediate models) are written to the // output folder. If a partially trained model with the same dataset and // parameters exists in that folder, training will be resumed. TrainGibbsLabeledLDA(modelPath, dataset, modelParams, trainingParams);
During training, the set of labels on each document is assumed fixed and observed, so the model will not use labels that are not present on the given document. However, after training is complete, you may be interested to see how much each label would be used if all labels were allowed to participate to some extent. To do so, we re-load the trained LabeledLDA model as just a regular LDA model and do inference as before, but using the labeled topics.
// Does inference on the same dataset, this time ignoring the assigned labels // and letting the model decide which labels to apply val model = GibbsLDA.loadInferenceModel(modelPath); val perDocWordTopicProbability = InferPerWordTopicDistributions(model, LDADataset(text)); DocumentTopicUsage(perDocWordTopicProbability) | CSVFile(modelPath, "usage-after-inference.csv");
You can use perDocWordTopicProbability.data.options if you want to directly inspect how each word is assigned to each underlying label.