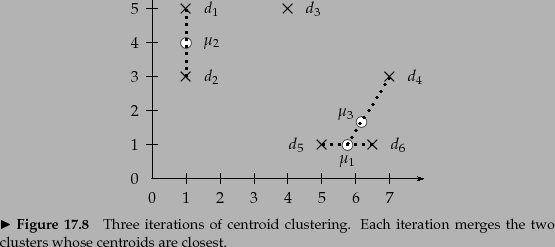
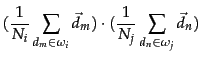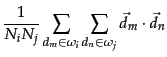Figure 17.11 shows the first three steps of a
centroid clustering.
The first two iterations form the clusters
![]() with centroid
with centroid ![]() and
and
![]() with centroid
with centroid ![]() because the pairs
because the pairs
![]() and
and
![]() have the highest centroid similarities. In the
third iteration, the highest
centroid similarity is between
have the highest centroid similarities. In the
third iteration, the highest
centroid similarity is between ![]() and
and ![]() producing the
cluster
producing the
cluster
![]() with centroid
with centroid ![]() .
.
Like GAAC,
centroid clustering is not best-merge persistent and
therefore
![]() (Exercise 17.10 ).
(Exercise 17.10 ).
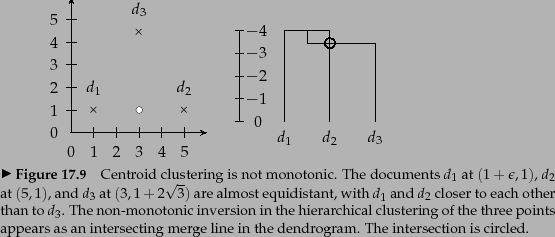
In contrast to the other three HAC algorithms,
centroid clustering is not monotonic.
So-called
inversions
can occur: Similarity can
increase during clustering as in the example in
Figure 17.12 , where we define similarity as negative distance.
In the first merge, the similarity of ![]() and
and ![]() is
is ![]() .
In the second merge, the similarity of the
centroid of
.
In the second merge, the similarity of the
centroid of ![]() and
and ![]() (the circle) and
(the circle) and ![]() is
is
![]() . This is an example of an
inversion: similarity increases in this sequence of
two clustering steps. In a monotonic HAC
algorithm, similarity is monotonically decreasing
from iteration to iteration.
. This is an example of an
inversion: similarity increases in this sequence of
two clustering steps. In a monotonic HAC
algorithm, similarity is monotonically decreasing
from iteration to iteration.
Increasing similarity in a series of HAC clustering steps contradicts the fundamental assumption that small clusters are more coherent than large clusters. An inversion in a dendrogram shows up as a horizontal merge line that is lower than the previous merge line. All merge lines in and 17.5 are higher than their predecessors because single-link and complete-link clustering are monotonic clustering algorithms.
Despite its non-monotonicity, centroid clustering is often used because its similarity measure - the similarity of two centroids - is conceptually simpler than the average of all pairwise similarities in GAAC. Figure 17.11 is all one needs to understand centroid clustering. There is no equally simple graph that would explain how GAAC works.
Exercises.