



Next: About this document ...
Up: irbook
Previous: Bibliography
Contents
- 1/0 loss
- The 1/0 loss case
- 11-point interpolated average precision
- Evaluation of ranked retrieval
- 20 Newsgroups
- Standard test collections
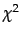 feature selection
feature selection
- Feature selectionChi2 Feature
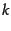 nearest neighbor classification
nearest neighbor classification
- k nearest neighbor
- -gram index
- k-gram indexes for wildcard
- -gram index
- k-gram indexes for spelling
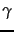 encoding
encoding
- Variable byte codes
- encoding
- Gamma codes
- encoding
- Gamma codes
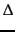 - codes
- codes
- Gamma codes
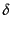 codes
codes
- Gamma codes
- - codes
- References and further reading
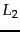 distance
distance
- Pivoted normalized document length
- A/B test
- Refining a deployed system
- Access control lists
- Other types of indexes
| Other types of indexes
| Other types of indexes
| Other types of indexes
- accumulator
- Weighted zone scoring
| Computing vector scores
- accuracy
- Evaluation of unranked retrieval
- active learning
- Choosing what kind of
- ad hoc retrieval
- An example information retrieval
| Text classification and Naive
- Add-one smoothing
- Naive Bayes text classification
| Naive Bayes text classification
- adjacency table
- Connectivity servers
- adversarial information retrieval
- Spam
- Akaike Information Criterion
- Cluster cardinality in K-means
- algorithmic search
- Advertising as the economic
- anchor text
- The web graph
- any-of classification
- The text classification problem
| Classification with more than
- authority score
- Hubs and Authorities
- Auxiliary index
- Dynamic indexing
| Dynamic indexing
- average-link clustering
- Group-average agglomerative clustering
- B-tree
- Search structures for dictionaries
- bag of words
- Term frequency and weighting
| Properties of Naive Bayes
- bag-of-words
- Properties of Naive Bayes
- balanced F measure
- Evaluation of unranked retrieval
- Bayes error rate
- Time complexity and optimality
- Bayes Optimal Decision Rule
- The 1/0 loss case
- Bayes risk
- The 1/0 loss case
- Bayes' Rule
- Review of basic probability
- Bayesian networks
- Bayesian network approaches to
- Bayesian prior
- Probability estimates in theory
- Bernoulli model
- The Bernoulli model
| The Bernoulli model
| The Bernoulli model
| Properties of Naive Bayes
| A variant of the
- best-merge persistence
- Time complexity of HAC
- bias
- The bias-variance tradeoff
- bias-variance tradeoff
- Types of language models
| Feature selection
| The bias-variance tradeoff
| Support vector machines: The
- biclustering
- References and further reading
- bigram language model
- Types of language models
- Binary Independence Model
- The Binary Independence Model
- binary tree
- Search structures for dictionaries
| Hierarchical clustering
- biword index
- Biword indexes
| Combination schemes
- blind relevance feedback
- see pseudo relevance feedback
- blocked sort-based indexing algorithm
- Blocked sort-based indexing
- Blocked sort-based indexing algorithm (BSBI)
- Blocked sort-based indexing
| Blocked sort-based indexing
| Other types of indexes
- blocked storage
- Blocked storage
- Blocked storage described
- Dictionary as a string
| Blocked storage
- blog
- XML retrieval
- BM25 weights
- Okapi BM25: a non-binary
- boosting
- References and further reading
- bottom-up clustering
- see hierarchical agglomerative clustering
- bowtie
- The web graph
- Break-even
- Evaluation of text classification
| Experimental results
- break-even point
- Evaluation of ranked retrieval
- BSBI
- Blocked sort-based indexing
- Buckshot algorithm
- Implementation notes
- Buffer
- Hardware basics
| Hardware basics
- caching
- A first take at
| Hardware basics
| Putting it all together
| Crawler architecture
| DNS resolution
- compression and
- Index compression
| Index compression
- defined
- Hardware basics
- capture-recapture method
- Index size and estimation
- cardinality
- in clustering
- Cardinality - the number
- CAS topics
- Evaluation of XML retrieval
- case-folding
- Capitalization/case-folding.
- Category
- The text classification problem
| The text classification problem
- centroid
- Rocchio classification
| K-means
- in relevance feedback
- The underlying theory.
- centroid-based classification
- References and further reading
- chain rule
- Review of basic probability
- chaining
- in clustering
- Single-link and complete-link clustering
- champion lists
- Tiered indexes
- class boundary
- Linear versus nonlinear classifiers
- Classes, defined
- The text classification problem
| The text classification problem
- Classes, maximum a posteriori
- Naive Bayes text classification
- classification
- Text classification and Naive
| Result ranking by machine
- Classification function
- The text classification problem
| The text classification problem
- Classification, defined
- Text classification and Naive
| Text classification and Naive
- classifier
- Probabilistic relevance feedback
- Classifiers, defined
- The text classification problem
- Classifiers, two-class
- Evaluation of text classification
- CLEF
- Standard test collections
- click spam
- Advertising as the economic
- clickstream mining
- Refining a deployed system
| Indirect relevance feedback
- clickthrough log analysis
- Refining a deployed system
- clique
- Single-link and complete-link clustering
- cluster
- Distributed indexing
| Flat clustering
- in relevance feedback
- When does relevance feedback
- cluster hypothesis
- Clustering in information retrieval
- cluster-based classification
- References and further reading
- cluster-internal labeling
- Cluster labeling
- Clusters
- defined
- Distributed indexing
- CO topics
- Evaluation of XML retrieval
- co-clustering
- References and further reading
- collection
- An example information retrieval
- collection frequency
- Dropping common terms: stop
| Frequency-based feature selection
- Collections
- statistics, large
- Other types of indexes
- combination similarity
- Hierarchical agglomerative clustering
| Single-link and complete-link clustering
| Optimality of HAC
| Optimality of HAC
- complete-link clustering
- Single-link and complete-link clustering
- complete-linkage clustering
- see complete-link clustering
- component coverage
- Evaluation of XML retrieval
- compound-splitter
- Tokenization
- compounds
- Tokenization
- Compression
- lossless / lossy
- Statistical properties of terms
- of dictionaries
- Zipf's law: Modeling the
| Blocked storage
- of postings list
- Blocked storage
| Gamma codes
- parameterized
- References and further reading
- Compression / indexes
- Heaps' law
- Statistical properties of terms
| Heaps' law: Estimating the
- Zipf's law
- Heaps' law: Estimating the
| Zipf's law: Modeling the
| Zipf's law: Modeling the
- Concept drift
- Properties of Naive Bayes
| Properties of Naive Bayes
| Evaluation of text classification
| References and further reading
| Choosing what kind of
- conditional independence assumption
- Deriving a ranking function
| Properties of Naive Bayes
| Properties of Naive Bayes
- confusion matrix
- Classification with more than
- connected component
- Single-link and complete-link clustering
- connectivity queries
- Connectivity servers
- connectivity server
- Connectivity servers
- content management system
- References and further reading
- Content management systems
- References and further reading
- context
- XML
- Basic XML concepts
- context resemblance
- A vector space model
- contiguity hypothesis
- Vector space classification
- continuation bit
- Variable byte codes
| Variable byte codes
- corpus
- An example information retrieval
- cosine similarity
- Dot products
| References and further reading
- CPC
- Advertising as the economic
- CPM
- Advertising as the economic
- Cranfield
- Standard test collections
- cross-entropy
- Extended language modeling approaches
- cross-language information retrieval
- Standard test collections
| References and further reading
- cumulative gain
- Evaluation of ranked retrieval
- data-centric XML
- XML retrieval
| Text-centric vs. data-centric XML
- database
- relational
- Boolean retrieval
| XML retrieval
| Text-centric vs. data-centric XML
- Databases
- communication with
- References and further reading
- decision boundary
- Rocchio classification
| Linear versus nonlinear classifiers
- decision hyperplane
- Vector space classification
| Linear versus nonlinear classifiers
- Decision trees
- Evaluation of text classification
| Evaluation of text classification
| References and further reading
- dendrogram
- Hierarchical agglomerative clustering
- development set
- Evaluation of text classification
- Development sets
- Evaluation of text classification
- development test collection
- Information retrieval system evaluation
- Dice coefficient
- Evaluation of ranked retrieval
- dictionary
- An example information retrieval
| A first take at
- differential cluster labeling
- Cluster labeling
- digital libraries
- XML retrieval
- Disk seek
- Hardware basics
- distortion
- Cluster cardinality in K-means
- distributed index
- Distributed indexing
| Distributed indexing
| References and further reading
- Distributed indexing
- Single-pass in-memory indexing
| Distributed indexing
| Distributed indexing
- distributed information retrieval
- see distributed crawling
| References and further reading
- divisive clustering
- Divisive clustering
- DNS resolution
- DNS resolution
- DNS server
- DNS resolution
- docID
- A first take at
- document
- An example information retrieval
| Choosing a document unit
- document collection
- see collection
- document frequency
- A first take at
| Inverse document frequency
| Frequency-based feature selection
- document likelihood model
- Extended language modeling approaches
- document partitioning
- Distributing indexes
- Document space
- The text classification problem
| The text classification problem
- document vector
- Tf-idf weighting
| The vector space model
- document-at-a-time
- Computing vector scores
| Impact ordering
- document-partitioned index
- Distributed indexing
- dot product
- Dot products
- Dynamic indexing
- Distributed indexing
- East Asian languages
- References and further reading
- edit distance
- Edit distance
- effectiveness
- An example information retrieval
| Evaluation of text classification
- Effectiveness, text classification
- Evaluation of text classification
| Evaluation of text classification
| Evaluation of text classification
- Efficiency
- Evaluation of text classification
- eigen decomposition
- Matrix decompositions
- eigenvalue
- Linear algebra review
- EM algorithm
- Model-based clustering
- email sorting
- Text classification and Naive
- Email, sorting
- Text classification and Naive
- enterprise resource planning
- References and further reading
- Enterprise search
- Index construction
| Index construction
- Entropy
- Gamma codes
| Gamma codes
| References and further reading
| Evaluation of clustering
- equivalence classes
- Normalization (equivalence classing of
- Ergodic Markov Chain
- Definition:
- Euclidean distance
- Pivoted normalized document length
| References and further reading
- Euclidean length
- Dot products
- Evalution of retrieval systems, text classification
- Evaluation of text classification
| Evaluation of text classification
- Evalution of retrieval systems, x
- Assessing as a
- evidence accumulation
- Designing parsing and scoring
- exclusive clustering
- A note on terminology.
- exhaustive clustering
- A note on terminology.
- expectation step
- Model-based clustering
- Expectation-Maximization algorithm
- Choosing what kind of
| Model-based clustering
- expected edge density
- References and further reading
- extended query
- Challenges in XML retrieval
- Extensible Markup Language
- XML retrieval
- external criterion of quality
- Evaluation of clustering
- External sorting algorithm
- Blocked sort-based indexing
| Blocked sort-based indexing
- false negative
- Evaluation of clustering
- false positive
- Evaluation of clustering
- feature engineering
- Features for text
- feature selection
- Feature selection
- Feature selection / text classification, greedy
- Comparison of feature selection
- Feature selection / text classification, method comparison
- Comparison of feature selection
- Feature selection / text classification, multiple classifiers
- Feature selection for multiple
| Feature selection for multiple
- Feature selection / text classification, mutual information
- Mutual information
- Feature selection / text classification, noise feature
- Feature selection
- Feature selection / text classification, overfitting
- Feature selection
- Feature selection / text classification, overview
- Feature selection
- Feature selection / text classification, statistical significance
- Feature selectionChi2 Feature
- Feature selection / text classification, x
- Feature selectionChi2 Feature
- Feature selection/text classification, frequency-based
- Frequency-based feature selection
| Frequency-based feature selection
- Feature selection/text classification, method comparison
- Comparison of feature selection
| Comparison of feature selection
- Feature selection/text classification, mutual information
- Mutual information
- Feature selection/text classification, overview
- Feature selection
- Feature selection/text classification, x
- Feature selectionChi2 Feature
- field
- Parametric and zone indexes
- filtering
- Text classification and Naive
| Text classification and Naive
| References and further reading
- first story detection
- Optimality of HAC
| References and further reading
- flat clustering
- Flat clustering
- focused retrieval
- References and further reading
- free text
- Scoring, term weighting and
| Vector space scoring and
- free text query
- see query, free text
| Computing vector scores
| Designing parsing and scoring
| XML retrieval
- frequency-based feature selection
- Frequency-based feature selection
- Frobenius norm
- Low-rank approximations
- Front coding
- Blocked storage
| Blocked storage
- functional margin
- Support vector machines: The
- F measure
- Evaluation of unranked retrieval
| References and further reading
- as an evaluation measure in clustering
- Evaluation of clustering
- GAAC
- Group-average agglomerative clustering
- generative model
- Finite automata and language
| The bias-variance tradeoff
| The bias-variance tradeoff
- geometric margin
- Support vector machines: The
- gold standard
- Information retrieval system evaluation
- Golomb codes
- References and further reading
| References and further reading
- GOV2
- Standard test collections
- greedy feature selection
- Comparison of feature selection
- grep
- An example information retrieval
- ground truth
- Information retrieval system evaluation
- group-average agglomerative clustering
- Group-average agglomerative clustering
- group-average clustering
- Group-average agglomerative clustering
- HAC
- Hierarchical agglomerative clustering
- hard assignment
- Flat clustering
- hard clustering
- Flat clustering
| A note on terminology.
- harmonic number
- Gamma codes
- Harmonic numbers
- Gamma codes
- Hashing
- Blocked storage
| Blocked storage
- Heaps' law
- Heaps' law: Estimating the
- held-out
- k nearest neighbor
- Held-out data
- Evaluation of text classification
| Evaluation of text classification
- hierarchic clustering
- Hierarchical clustering
- hierarchical agglomerative clustering
- Hierarchical agglomerative clustering
- hierarchical classification
- Large and difficult category
| References and further reading
- hierarchical clustering
- Flat clustering
| Hierarchical clustering
- Hierarchical Dirichlet Processes
- References and further reading
- hierarchy
- in clustering
- Hierarchical clustering
- highlighting
- Challenges in XML retrieval
- HITS
- Hubs and Authorities
- HTML
- Background and history
- http
- Background and history
- hub score
- Hubs and Authorities
- hyphens
- Tokenization
- i.i.d.
- Evaluation of text classification
| see independent and identically distributed
- Ide dec-hi
- The Rocchio (1971) algorithm.
- idf
- Other types of indexes
| Challenges in XML retrieval
| Probability estimates in practice
| Okapi BM25: a non-binary
- iid
- see independent and identically distributed
- impact
- Other types of indexes
- implicit relevance feedback
- Indirect relevance feedback
- in-links
- The web graph
| Link analysis
- incidence matrix
- An example information retrieval
| Term-document matrices and singular
- Independence
- Feature selectionChi2 Feature
| Feature selectionChi2 Feature
- independent and identically distributed
- Evaluation of text classification
- in clustering
- Cluster cardinality in K-means
- Independent and identically distributed ( IID )
- Evaluation of text classification
- index
- An example information retrieval
| see permuterm index
| see alsoparametric index, zone index
- index construction
- Index construction
- resources
- References and further reading
- Indexer
- Index construction
| Index construction
- indexing
- Index construction
- defined
- Index construction
- sort-based
- A first take at
- indexing granularity
- Choosing a document unit
- indexing unit
- Challenges in XML retrieval
- INEX
- Evaluation of XML retrieval
- Information gain
- Evaluation of text classification
| Evaluation of text classification
- information need
- An example information retrieval
| Information retrieval system evaluation
- information retrieval
- Boolean retrieval
- hardware issues
- Index construction
| Hardware basics
- terms , statistical properties of
- Index compression
| Zipf's law: Modeling the
- informational queries
- User query needs
- inner product
- Dot products
- instance-based learning
- Time complexity and optimality
- internal criterion of quality
- Evaluation of clustering
- interpolated precision
- Evaluation of ranked retrieval
- intersection
- postings list
- Processing Boolean queries
- inverse document frequency
- Inverse document frequency
| Computing vector scores
- inversion
- Blocked sort-based indexing
| Hierarchical agglomerative clustering
| Centroid clustering
- Inversions
- defined
- Blocked sort-based indexing
- inverted file
- see inverted index
- inverted index
- An example information retrieval
- inverted list
- see postings list
- Inverter
- Distributed indexing
| Distributed indexing
| Distributed indexing
- IP address
- DNS resolution
- Jaccard coefficient
- k-gram indexes for spelling
| Near-duplicates and shingling
- k nearest neighbor classification (kNN), multinomial Naive Bayes vs., 249.57 k nearest neighbor classification (kNN), as nonlinear classification
- Properties of Naive Bayes
- K-medoids
- K-means
- kappa statistic
- Assessing relevance
| References and further reading
| References and further reading
- kernel
- Nonlinear SVMs
- kernel function
- Nonlinear SVMs
- kernel trick
- Nonlinear SVMs
- key-value pairs
- Distributed indexing
- keyword-in-context
- Results snippets
- kNN classification
- k nearest neighbor
- Kruskal's algorithm
- References and further reading
- Kullback-Leibler divergence
- Extended language modeling approaches
| Exercises
| References and further reading
- KWIC
- see keyword-in-context
- label
- The text classification problem
- labeling
- Text classification and Naive
- Labeling, defined
- Text classification and Naive
- language
- Finite automata and language
- language identification
- Tokenization
| References and further reading
- language model
- Finite automata and language
- Laplace smoothing
- Naive Bayes text classification
- Latent Dirichlet Allocation
- References and further reading
- latent semantic indexing
- Latent semantic indexing
- LDA
- References and further reading
- learning algorithm
- The text classification problem
- learning error
- The bias-variance tradeoff
- learning method
- The text classification problem
- lemma
- Stemming and lemmatization
- lemmatization
- Stemming and lemmatization
- lemmatizer
- Stemming and lemmatization
- length-normalization
- Dot products
- Levenshtein distance
- Edit distance
- lexicalized subtree
- A vector space model
- lexicon
- An example information retrieval
- likelihood
- Review of basic probability
- likelihood ratio
- Finite automata and language
- linear classifier
- Linear versus nonlinear classifiers
| A simple example of
- linear problem
- Linear versus nonlinear classifiers
- linear separability
- Linear versus nonlinear classifiers
- link farms
- References and further reading
- link spam
- Spam
| Link analysis
- LLRUN
- References and further reading
- LM
- Using query likelihood language
- Logarithmic merging
- Dynamic indexing
| Dynamic indexing
| Dynamic indexing
- lossless
- Statistical properties of terms
- lossy compression
- Statistical properties of terms
- low-rank approximation
- Low-rank approximations
- LSA
- Latent semantic indexing
- LSI as soft clustering
- Latent semantic indexing
- machine translation
- Types of language models
| Using query likelihood language
| Extended language modeling approaches
- machine-learned relevance
- Learning weights
| A simple example of
- Macroaveraging
- Evaluation of text classification
| Evaluation of text classification
| Evaluation of text classification
- MAP
- Evaluation of ranked retrieval
| Probability estimates in theory
| Naive Bayes text classification
- Map phase
- Distributed indexing
| Distributed indexing
- MapReduce
- Distributed indexing
| Distributed indexing
| Distributed indexing
| Distributed indexing
| References and further reading
- margin
- Support vector machines: The
- marginal relevance
- Critiques and justifications of
- marginal statistic
- Assessing relevance
- Master node
- Distributed indexing
| Distributed indexing
- matrix decomposition
- Matrix decompositions
- maximization step
- Model-based clustering
- maximum a posteriori
- Probability estimates in theory
| Properties of Naive Bayes
- maximum a posteriori class
- Naive Bayes text classification
- maximum likelihood estimate
- Probability estimates in theory
| Naive Bayes text classification
- Maximum likelihood estimate ( MLE )
- Naive Bayes text classification
- Maximum likelihood estimate (MLE)
- Mutual information
- maximum likelihood estimation
- Estimating the query generation
- Mean Average Precision
- see MAP
- medoid
- K-means
- memory capacity
- The bias-variance tradeoff
- memory-based learning
- Time complexity and optimality
- Mercator
- Crawling
- Mercer kernel
- Nonlinear SVMs
- merge
- postings
- Processing Boolean queries
- merge algorithm
- Processing Boolean queries
- metadata
- Tokenization
| Parametric and zone indexes
| Results snippets
| Basic XML concepts
| References and further reading
| Spam
- microaveraging
- Evaluation of text classification
- minimum spanning tree
- References and further reading
| Exercises
- minimum variance clustering
- References and further reading
- MLE
- see maximum likelihood estimate
- ModApte split
- Evaluation of text classification
| Evaluation of text classification
| References and further reading
- model complexity
- The bias-variance tradeoff
| Cluster cardinality in K-means
- model-based clustering
- Model-based clustering
- monotonicity
- Hierarchical agglomerative clustering
- multiclass classification
- Classification with more than
- multiclass SVM
- References and further reading
- multilabel classification
- Classification with more than
- multimodal class
- Rocchio classification
- Multinomial Naive Bayes, random variable X / U
- Properties of Naive Bayes
- multinomial classification
- Classification with more than
- multinomial distribution
- Multinomial distributions over words
- Multinomial model
- Relation to multinomial unigram
| Relation to multinomial unigram
| The Bernoulli model
| A variant of the
- multinomial Naive Bayes
- Naive Bayes text classification
- Multinomial Naive Bayes, in text classification
- Naive Bayes text classification
- Multinomial Naive Bayes, in text classification
- Relation to multinomial unigram
- Multinomial Naive Bayes, optimal classifier
- Properties of Naive Bayes
- Multinomial Naive Bayes, positional independence assumption
- Naive Bayes text classification
| Properties of Naive Bayes
- Multinomial Naive Bayes, sparseness
- Naive Bayes text classification
- multinomial NB
- see multinomial Naive Bayes
- multivalue classification
- Classification with more than
- multivariate Bernoulli model
- The Bernoulli model
- mutual information
- Mutual information
| Evaluation of clustering
- Naive Bayes assumption
- Deriving a ranking function
- named entity tagging
- XML retrieval
| Features for text
- National Institute of Standards and Technology
- Standard test collections
- natural language processing
- Book organization and course
| Stemming and lemmatization
| Results snippets
| References and further reading
| Language modeling versus other
| Model-based clustering
- navigational queries
- User query needs
- NDCG
- Evaluation of ranked retrieval
- nested elements
- Challenges in XML retrieval
- NEXI
- Basic XML concepts
- next word index
- Combination schemes
- Nibble
- Variable byte codes
| Variable byte codes
- NLP
- see natural language processing
- NMI
- Evaluation of clustering
- noise document
- Linear versus nonlinear classifiers
- noise feature
- Properties of Naive Bayes
| Feature selection
- nonlinear classifier
- Linear versus nonlinear classifiers
- nonlinear problem
- Linear versus nonlinear classifiers
- normal vector
- Rocchio classification
- normalized discounted cumulative gain
- Evaluation of ranked retrieval
- normalized mutual information
- Evaluation of clustering
- novelty detection
- Optimality of HAC
- NTCIR
- Standard test collections
| References and further reading
- objective function
- Problem statement
| K-means
- odds
- Review of basic probability
- odds ratio
- Deriving a ranking function
- Okapi weighting
- Okapi BM25: a non-binary
- one-of classification
- The text classification problem
| Evaluation of text classification
| Evaluation of text classification
| Classification with more than
- optimal classifier
- Properties of Naive Bayes
| The bias-variance tradeoff
- optimal clustering
- Optimality of HAC
- optimal learning method
- The bias-variance tradeoff
- ordinal regression
- Result ranking by machine
- out-links
- The web graph
- outlier
- K-means
- overfitting
- Feature selection
| The bias-variance tradeoff
- Oxford English Dictionary
- Statistical properties of terms
- PageRank
- PageRank
- paid inclusion
- Spam
- parameter tuning
- Information retrieval system evaluation
| References and further reading
| References and further reading
| References and further reading
- parameter tying
- Separate feature spaces for
- parameter-free compression
- Gamma codes
- parameterized compression
- References and further reading
- parametric index
- Parametric and zone indexes
- parametric search
- XML retrieval
- Parser
- Distributed indexing
| Distributed indexing
- partition rule
- Review of basic probability
- partitional clustering
- A note on terminology.
- passage retrieval
- References and further reading
- patent databases
- XML retrieval
- perceptron algorithm
- References and further reading
| References and further reading
- performance
- Evaluation of text classification
- permuterm index
- Permuterm indexes
- personalized PageRank
- Topic-specific PageRank
- phrase index
- Biword indexes
- phrase queries
- Positional postings and phrase
| References and further reading
- phrase search
- The extended Boolean model
- pivoted document length normalization
- Pivoted normalized document length
- Pointwise mutual information
- Mutual information
| References and further reading
| References and further reading
- polychotomous
- Classification with more than
- polytomous classification
- Classification with more than
- polytope
- k nearest neighbor
- pooling
- Assessing relevance
| References and further reading
- pornography filtering
- Text classification and Naive
| Features for text
- Porter stemmer
- Stemming and lemmatization
- positional independence
- Properties of Naive Bayes
- positional index
- Positional indexes
- posterior probability
- Review of basic probability
- posting
- An example information retrieval
| An example information retrieval
| A first take at
| Blocked sort-based indexing
| Index compression
- Postings
- compression and
- Index compression
- in block sort-based indexing
- Blocked sort-based indexing
- postings list
- An example information retrieval
- power law
- Zipf's law: Modeling the
| The web graph
- precision
- An example information retrieval
| Evaluation of unranked retrieval
- precision at
- Evaluation of ranked retrieval
- precision-recall curve
- Evaluation of ranked retrieval
- prefix-free code
- Gamma codes
- Preprocessing, effects of
- Statistical properties of terms
- principal direction divisive partitioning
- References and further reading
- principal left eigenvector
- Markov chains
- prior probability
- Review of basic probability
- Probability Ranking Principle
- The 1/0 loss case
- probability vector
- Markov chains
- prototype
- Vector space classification
- proximity operator
- The extended Boolean model
- proximity weighting
- Query-term proximity
- pseudo relevance feedback
- Pseudo relevance feedback
- pseudocounts
- Probability estimates in theory
- pull model
- References and further reading
- purity
- Evaluation of clustering
- push model
- References and further reading
- Quadratic Programming
- Support vector machines: The
- query
- An example information retrieval
- free text
- The extended Boolean model
| The extended Boolean model
| Term frequency and weighting
- simple conjunctive
- Processing Boolean queries
- query expansion
- Query expansion
- query likelihood model
- Using query likelihood language
- query optimization
- Processing Boolean queries
- query-by-example
- Basic XML concepts
| Language modeling versus other
- R-precision
- Evaluation of ranked retrieval
| References and further reading
- Rand index
- Evaluation of clustering
- adjusted
- References and further reading
- random variable
- Review of basic probability
- random variable
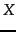
- Properties of Naive Bayes
- random variable
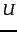
- Properties of Naive Bayes
- random variable
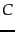
- Properties of Naive Bayes
- Random variables, C
- Properties of Naive Bayes
- rank
- Linear algebra review
- Ranked Boolean retrieval
- Weighted zone scoring
- ranked retrieval
- Other types of indexes
| References and further reading
- model
- The extended Boolean model
- Ranked retrieval models
- described
- Other types of indexes
- ranking SVM
- Result ranking by machine
- recall
- An example information retrieval
| Evaluation of unranked retrieval
- Reduce phase
- Distributed indexing
| Distributed indexing
- reduced SVD
- Term-document matrices and singular
| Low-rank approximations
- regression
- Result ranking by machine
- regular expressions
- An example information retrieval
| References and further reading
- regularization
- Soft margin classification
- relational database
- XML retrieval
| Text-centric vs. data-centric XML
- relative frequency
- Probability estimates in theory
- relevance
- An example information retrieval
| Information retrieval system evaluation
- relevance feedback
- Relevance feedback and pseudo
- residual sum of squares
- K-means
- results snippets
- Putting it all together
- retrieval model
- Boolean
- An example information retrieval
- Retrieval Status Value
- Deriving a ranking function
- retrieval systems
- Other types of indexes
- Reuters-21578
- Standard test collections
- Reuters-21578 collection, text classification in
- Evaluation of text classification
| Evaluation of text classification
| Evaluation of text classification
| Evaluation of text classification
- Reuters-RCV1
- Blocked sort-based indexing
| Standard test collections
- Reuters-RCV1 collection
- described
- Blocked sort-based indexing
| Blocked sort-based indexing
| References and further reading
- dictionary-as-a-string storage
- Dictionary compression
| Dictionary as a string
- RF
- Relevance feedback and pseudo
- Robots Exclusion Protocol
- Crawler architecture
- ROC curve
- Evaluation of ranked retrieval
- Rocchio algorithm
- The Rocchio (1971) algorithm.
- Rocchio classification
- Rocchio classification
- Routing
- Text classification and Naive
| Text classification and Naive
| References and further reading
- RSS
- K-means
- rule of 30
- Statistical properties of terms
- Rules in text classification
- Text classification and Naive
| Text classification and Naive
- Scatter-Gather
- Clustering in information retrieval
- schema
- Basic XML concepts
- schema diversity
- Challenges in XML retrieval
- schema heterogeneity
- Challenges in XML retrieval
- search advertising
- Advertising as the economic
- search engine marketing
- Advertising as the economic
- Search Engine Optimizers
- Spam
- search result clustering
- Clustering in information retrieval
- search results
- Clustering in information retrieval
- security
- Other types of indexes
| Other types of indexes
- seed
- K-means
- seek time
- Hardware basics
- Segment file
- Distributed indexing
| Distributed indexing
- semi-supervised learning
- Choosing what kind of
- semistructured query
- XML retrieval
- semistructured retrieval
- Boolean retrieval
| XML retrieval
- sensitivity
- Evaluation of ranked retrieval
- sentiment detection
- Text classification and Naive
| Text classification and Naive
- Sequence model
- Properties of Naive Bayes
| Properties of Naive Bayes
- shingling
- Near-duplicates and shingling
- single-label classification
- Classification with more than
- single-link clustering
- Single-link and complete-link clustering
- single-linkage clustering
- see single-link clustering
- single-pass in-memory indexing
- Single-pass in-memory indexing
- Single-pass in-memory indexing (SPIMI)
- Blocked sort-based indexing
| Single-pass in-memory indexing
| References and further reading
- singleton
- Hierarchical agglomerative clustering
- singleton cluster
- K-means
- singular value decomposition
- Term-document matrices and singular
- skip list
- Faster postings list intersection
| References and further reading
- slack variables
- Soft margin classification
- SMART
- The Rocchio (1971) algorithm.
- smoothing
- Maximum tf normalization
| Probability estimates in theory
- add
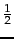
- Probability estimates in theory
- add
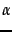
- Probability estimates in theory
- add
- Probability estimates in theory
- add
- Probabilistic approaches to relevance
- add
- Probabilistic approaches to relevance
- add
- Okapi BM25: a non-binary
- add
- Relation to multinomial unigram
- Bayesian prior
- Probability estimates in theory
| Probabilistic approaches to relevance
| Estimating the query generation
- linear interpolation
- Estimating the query generation
- snippet
- Results snippets
- soft assignment
- Flat clustering
- soft clustering
- Flat clustering
| A note on terminology.
| Hierarchical clustering
- Sort-based multiway merge
- References and further reading
- sorting
- in index construction
- A first take at
- soundex
- Phonetic correction
- spam
- Features for text
| Spam
- email
- Text classification and Naive
- web
- Text classification and Naive
- sparseness
- Types of language models
| Estimating the query generation
| Naive Bayes text classification
- specificity
- Evaluation of ranked retrieval
- spectral clustering
- References and further reading
- speech recognition
- Types of language models
- spelling correction
- Putting it all together
| Types of language models
| Multinomial distributions over words
- spider
- Overview
- spider traps
- Index size and estimation
- SPIMI
- Single-pass in-memory indexing
- splits
- Distributed indexing
- sponsored search
- Advertising as the economic
- Standing query
- Text classification and Naive
| Text classification and Naive
- static quality scores
- Static quality scores and
- static web pages
- Web characteristics
- statistical significance
- Feature selectionChi2 Feature
- Statistical text classification
- Text classification and Naive
| Text classification and Naive
- steady-state
- Definition:
| The PageRank computation
- stemming
- Stemming and lemmatization
| References and further reading
- stochastic matrix
- Markov chains
- stop list
- Dropping common terms: stop
- stop words
- Term frequency and weighting
- stop words
- Tokenization
| Dropping common terms: stop
| Combination schemes
| Term frequency and weighting
| Maximum tf normalization
- structural SVM
- Result ranking by machine
- structural SVMs
- Multiclass SVMs
- structural term
- A vector space model
- structured document retrieval principle
- Challenges in XML retrieval
- structured query
- XML retrieval
- structured retrieval
- XML retrieval
| XML retrieval
- summarization
- References and further reading
- summary
- dynamic
- Results snippets
- static
- Results snippets
- Supervised learning
- The text classification problem
| The text classification problem
- support vector
- Support vector machines: The
- support vector machine
- Support vector machines and
| References and further reading
- multiclass
- Multiclass SVMs
- Support vector machines ( SVMs ) , effectiveness
- Evaluation of text classification
- SVD
- References and further reading
| References and further reading
| Term-document matrices and singular
- SVM
- see support vector machine
- symmetric diagonal decomposition
- Matrix decompositions
| Term-document matrices and singular
| Term-document matrices and singular
- synonymy
- Relevance feedback and query
- teleport
- PageRank
- term
- An example information retrieval
| The term vocabulary and
| Tokenization
- term frequency
- The extended Boolean model
| Term frequency and weighting
- term normalization
- Normalization (equivalence classing of
- term partitioning
- Distributing indexes
- term-at-a-time
- Computing vector scores
| Impact ordering
- term-document matrix
- Dot products
- term-partitioned index
- Distributed indexing
- termID
- Blocked sort-based indexing
- Test data
- The text classification problem
| The text classification problem
- test set
- The text classification problem
| Evaluation of text classification
- text categorization
- Text classification and Naive
- text classification
- Text classification and Naive
- Text classification, defined
- Text classification and Naive
- Text classification, feature selection
- Feature selection
| Comparison of feature selection
- Text classification, overview
- The text classification problem
| The text classification problem
- Text classification, vertical search engines
- Text classification and Naive
- text summarization
- Results snippets
- text-centric XML
- Text-centric vs. data-centric XML
- tf
- see term frequency
- tf-idf
- Tf-idf weighting
- tiered indexes
- Tiered indexes
- token
- The term vocabulary and
| Tokenization
- token normalization
- Normalization (equivalence classing of
- top docs
- References and further reading
- top-down clustering
- Divisive clustering
- topic
- Standard test collections
| Text classification and Naive
- in XML retrieval
- Evaluation of XML retrieval
- topic classification
- Text classification and Naive
- topic spotting
- Text classification and Naive
- topic-specific PageRank
- Topic-specific PageRank
- topical relevance
- Evaluation of XML retrieval
- training set
- The text classification problem
| Evaluation of text classification
- transactional query
- User query needs
- transductive SVMs
- Choosing what kind of
- translation model
- Extended language modeling approaches
- TREC
- Standard test collections
| References and further reading
- trec_eval
- References and further reading
- truecasing
- Capitalization/case-folding.
| References and further reading
- truncated SVD
- Term-document matrices and singular
| Low-rank approximations
| Latent semantic indexing
- two-class classifier
- Evaluation of text classification
- type
- Tokenization
- unary code
- Gamma codes
- unigram language model
- Types of language models
- union-find algorithm
- Optimality of HAC
| Near-duplicates and shingling
- universal code
- Gamma codes
- unsupervised learning
- Flat clustering
- URL
- Background and history
- URL normalization
- Crawler architecture
- Utility measure
- References and further reading
| References and further reading
- Variable byte encoding
- Postings file compression
| Variable byte codes
| Variable byte codes
- variance
- The bias-variance tradeoff
- vector space model
- The vector space model
- vertical search engine
- Text classification and Naive
- vocabulary
- An example information retrieval
- Voronoi tessellation
- k nearest neighbor
- Ward's method
- References and further reading
- web crawler
- Overview
- weight vector
- Support vector machines: The
- weighted zone scoring
- Parametric and zone indexes
- Wikipedia
- Evaluation of XML retrieval
- wildcard query
- An example information retrieval
| Dictionaries and tolerant retrieval
| Wildcard queries
- within-point scatter
- Exercises
- word segmentation
- Tokenization
- XML
- Obtaining the character sequence
| XML retrieval
- XML attribute
- Basic XML concepts
- XML DOM
- Basic XML concepts
- XML DTD
- Basic XML concepts
- XML element
- Basic XML concepts
- XML fragment
- References and further reading
- XML Schema
- Basic XML concepts
- XML tag
- Basic XML concepts
- XPath
- Basic XML concepts
- Zipf's law
- Zipf's law: Modeling the
- zone
- Parametric and zone indexes
| Improving classifier performance
| Document zones in text
| Connections to text summarization.
- zone index
- Parametric and zone indexes
- zone search
- XML retrieval
© 2008 Cambridge University Press
This is an automatically generated page. In case of formatting errors you may want to look at the PDF edition of the book.
2009-04-07