




Next: Champion lists
Up: Efficient scoring and ranking
Previous: Inexact top K document
Contents
Index
Index elimination
For a multi-term query 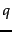 , it is clear we only consider documents containing at least one of the query terms. We can take this a step further using additional heuristics:
, it is clear we only consider documents containing at least one of the query terms. We can take this a step further using additional heuristics:
- We only consider documents containing terms whose idf exceeds a preset threshold. Thus, in the postings traversal, we only traverse the postings for terms with high idf. This has a fairly significant benefit: the postings lists of low-idf terms are generally long; with these removed from contention, the set of documents for which we compute cosines is greatly reduced. One way of viewing this heuristic: low-idf terms are treated as stop words and do not contribute to scoring. For instance, on the query catcher in the rye, we only traverse the postings for catcher and rye. The cutoff threshold can of course be adapted in a query-dependent manner.
- We only consider documents that contain many (and as a special case, all) of the query terms. This can be accomplished during the postings traversal; we only compute scores for documents containing all (or many) of the query terms. A danger of this scheme is that by requiring all (or even many) query terms to be present in a document before considering it for cosine computation, we may end up with fewer than
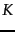 candidate documents in the output. This issue will discussed further in Section 7.2.1 .
candidate documents in the output. This issue will discussed further in Section 7.2.1 .
Next: Champion lists
Up: Efficient scoring and ranking
Previous: Inexact top K document
Contents
Index
© 2008 Cambridge University Press
This is an automatically generated page. In case of formatting errors you may want to look at the PDF edition of the book.
2009-04-07