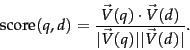There is a far more compelling reason to represent documents
as vectors: we can also view a query as a
vector. Consider the query ![]() jealous gossip. This
query turns into the unit vector
jealous gossip. This
query turns into the unit vector
![]() on the three coordinates of
Figures 6.12 and 6.13. The key
idea now: to assign to each document
on the three coordinates of
Figures 6.12 and 6.13. The key
idea now: to assign to each document ![]() a score equal to
the dot product
a score equal to
the dot product
| (26) |
In the example of Figure 6.13, Wuthering Heights is the top-scoring document for this query with a score of 0.509, with Pride and Prejudice a distant second with a score of 0.085, and Sense and Sensibility last with a score of 0.074. This simple example is somewhat misleading: the number of dimensions in practice will be far larger than three: it will equal the vocabulary size ![]() .
.
To summarize, by viewing a query as a ``bag of words'', we are able to treat it as a very short document. As a consequence, we can use the cosine similarity between the query vector and a document vector as a measure of the score of the document for that query. The resulting scores can then be used to select the top-scoring documents for a query. Thus we have
Computing the cosine similarities between the query vector and each document vector in the collection, sorting the resulting scores and selecting the top ![]() documents can be expensive -- a single similarity computation can entail a dot product in tens of thousands of dimensions, demanding tens of thousands of arithmetic operations. In Section 7.1 we study how to use an inverted index for this purpose, followed by a series of heuristics for improving on this.
documents can be expensive -- a single similarity computation can entail a dot product in tens of thousands of dimensions, demanding tens of thousands of arithmetic operations. In Section 7.1 we study how to use an inverted index for this purpose, followed by a series of heuristics for improving on this.
Worked example.
We now consider the query best car insurance on a fictitious collection with
![]() documents where the document frequencies of auto, best, car and insurance are respectively 5000, 50000, 10000 and 1000.
documents where the document frequencies of auto, best, car and insurance are respectively 5000, 50000, 10000 and 1000.
| term | query | document | product | |||||
| tf | df | idf |
|
tf | wf |
|
||
| auto | 0 | 5000 | 2.3 | 0 | 1 | 1 | 0.41 | 0 |
| best | 1 | 50000 | 1.3 | 1.3 | 0 | 0 | 0 | 0 |
| car | 1 | 10000 | 2.0 | 2.0 | 1 | 1 | 0.41 | 0.82 |
| insurance | 1 | 1000 | 3.0 | 3.0 | 2 | 2 | 0.82 | 2.46 |
In this example the weight of a term in the query is simply the idf (and zero for a term not in the query, such as auto); this is reflected in the column header
![]() (the entry for auto is zero because the query does not contain the termauto). For documents, we use tf weighting with no use of idf but with Euclidean normalization. The former is shown under the column headed wf, while the latter is shown under the column headed
(the entry for auto is zero because the query does not contain the termauto). For documents, we use tf weighting with no use of idf but with Euclidean normalization. The former is shown under the column headed wf, while the latter is shown under the column headed
![]() . Invoking (23) now gives a net score of
. Invoking (23) now gives a net score of
![]() .
End worked example.
.
End worked example.