Software > Stanford TokensRegex
About | Download | Usage | Questions | Mailing lists | Release history
About
TokensRegex is a generic framework included in Stanford CoreNLP for defining patterns over text (sequences of tokens) and mapping it to semantic objects represented as Java objects. TokensRegex emphasizes describing text as a sequence of tokens (words, punctuation marks, etc.), which may have additional attributes, and writing patterns over those tokens, rather than working at the character level, as with standard regular expression packages. For example, you might match names of people who are painters with a TokensRegex pattern like this:
([ner: PERSON]+) /was|is/ /an?/ []{0,3} /painter|artist/
As part of the framework, TokensRegex provides the following:
- A pattern language for mapping textual expressions to Java objects
- A utility for matching patterns over token sequences
- Integration with the Stanford CoreNLP pipeline with access to all annotations offered by the Stanford CoreNLP pipeline
TokensRegex was used to develop SUTime, a rule-based temporal tagger for recognizing and normalizing temporal expressions. An included set of slides provides an overview of this package. There is quite detailed Javadoc for several of the key classes: for the matching patterns, see the Javadoc for TokenSequencePattern and for actions, see the Javadoc for Expressions. Some additional information is available in a set of older slides.
If you use TokensRegex, please cite:
Angel X. Chang and Christopher D. Manning. 2014. TokensRegex: Defining cascaded regular expressions over tokens. Stanford University Technical Report, 2014. [bib]
TokensRegex was written by Angel Chang. These programs also rely on classes developed by others as part of the Stanford JavaNLP project.
Usage
Annotators
The Stanford CoreNLP pipeline provides two annotators that use TokensRegex to provide annotations based on regular expressions over tokens. They can be configured and added to the CoreNLP pipeline as custom annotators.| Class | Generated Annotations | Description |
|---|---|---|
| TokensRegexNERAnnotator | NamedEntityTagAnnotation | Implements a simple, rule-based NER over token sequences using Java regular expressions. The goal of this Annotator is to provide a simple framework to incorporate NE labels that are not annotated in traditional NL corpora, but are easily recognized by rule-based techniques. For example, the default list of regular expressions that we distribute in the models file recognizes ideologies (IDEOLOGY), nationalities (NATIONALITY), religions (RELIGION), and titles (TITLE). This annotator is similar to RegexNERAnnotator but supports TokensRegex expressions as well as NER annotations using regular expressions specified in a file. |
| TokensRegexAnnotator | Custom | A more generic annotator that uses TokensRegex rules to define what patterns to match and what to annotate. This annotator is much more flexible than the TokensRegexNERAnnotator, but is also more complicated to use. It takes as input files of TokensRegex rules and extracts matched expressions using the Extraction Pipeline. |
Usage from the command line
The edu.stanford.nlp.ling.tokensregex.demo package includes several utility programs with a main method that you can use to test and evaluate TokensRegex from the command line.
TokensRegexAnnotatorDemo works by running the TokensRegexAnnotator discussed above. It takes two arguments: a rules file and a file to annotator (either of which may be ommitted and a default is used. It prints a hardcoded set of token attributes, but you will be able to seee the results if you override the lemma or NER, say.
java edu.stanford.nlp.ling.tokensregex.demo.TokensRegexAnnotatorDemo myfile.tokensregex myfile.txt
Usage in Java code
TokensRegex can also be used programmatically with Java code.
- To match a regular expression over tokens
Programmatically, TokensRegex follows a similar paradigm as the Java regular expression library. Regular expressions are defined using a string which is then compiled into a
TokenSequencePattern. For a given sequence of tokens aTokenSequenceMatcheris created that can match the pattern against that sequence. This allows theTokensSequencePatternto be compiled just once. The regular expression language over tokens is described under Pattern Language, below.Example Usage:
List<CoreLabel> tokens = ...; TokenSequencePattern pattern = TokenSequencePattern.compile(...); TokenSequenceMatcher matcher = pattern.getMatcher(tokens); while (matcher.find()) { String matchedString = matcher.group(); List<CoreMap> matchedTokens = matcher.groupNodes(); ... }The
TokenSequenceMatcherprovides similar methods for obtaining the results as a JavaMatcher. In addition, it offers methods to access the matched sequence of tokens (e.g.,groupNodes). For a full list, see SequenceMatchResult. -
To match multiple regular expressions over tokens
Often you may have not just one, but many regular expressions that you would like to match. TokensRegex provides a utility class, MultiPatternMatcher for matching against multiple regular expressions. It gives higher performance than matching many patterns in turn.
Example Usage:
List<CoreLabel> tokens = ...; List<TokenSequencePattern> tokenSequencePatterns = ...; MultiPatternMatcher multiMatcher = TokenSequencePattern.getMultiPatternMatcher(tokenSequencePatterns); // Finds all non-overlapping sequences using specified list of patterns // When multiple patterns overlap, matches selected based on priority, length, etc. List<SequenceMatchResult<CoreMap>> multiMatcher.findNonOverlapping(tokens);For more complicated use cases, TokensRegex provides a pipeline for matching against multiple regular expressions in stages. It also provides a language for defining rules and for how the expression should be matched. The CoreMapExpressionExtractor class reads the TokensRegex rules from a file and uses the TokensRegex pipeline to extract matched expressions. This is used by the TokensRegexAnnotator and for developing SUTime.
List<CoreMap> sentences = ...; CoreMapExpressionExtractor extractor = CoreMapExpressionExtractor.createExtractorFromFiles(TokenSequencePattern.getNewEnv(), file1, file2,...); for (CoreMap sentence:sentences) { List<MatchedExpression> matched = extractor.extractExpressions(sentence); ... }
TokensRegex Extraction Pipeline
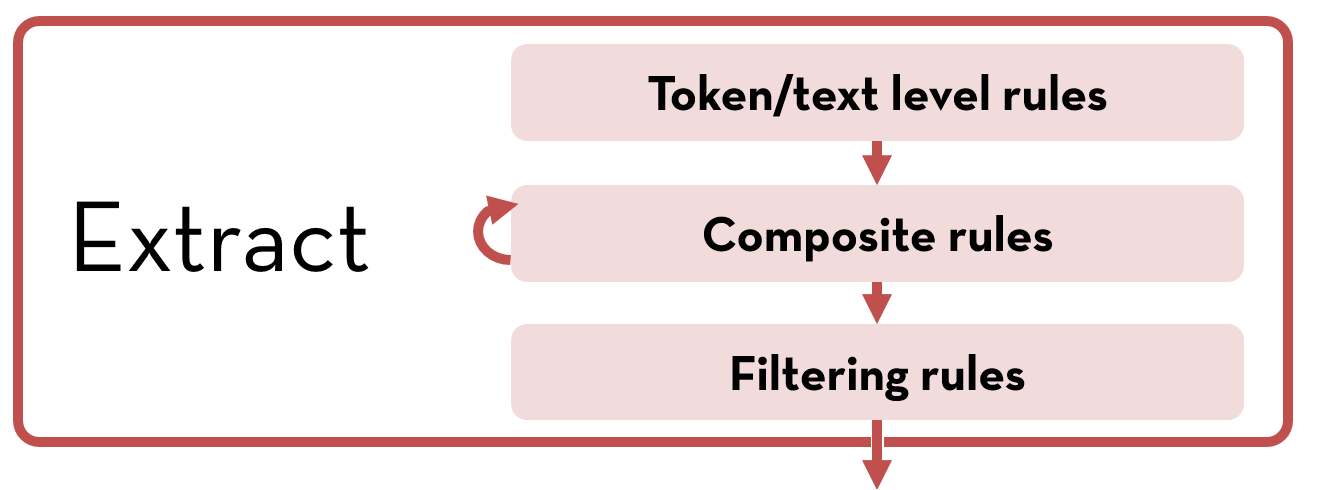
The TokensRegex pipeline reads extraction rules from a file and applies the rules in stages. Each rule consists of a pattern to match, a possible action, and a result (see TokensRegex Rules for details on the format of the rules).
There are four types of extraction rules: text, tokens, composite and filter. In each stage, the extraction rules are applied as follows:
- At the beginning of each stage, the extraction rules over text or tokens are applied. Only non-overlapping matches with resulting values are kept.
- Next, composite rules are applied repeatedly until no changes are detected.
- At the end of each stage, the filter rules are applied to discard any expressions that should not be matched.
Within each sub-stage, overlapping matches are resolved based on the priority of the rules, length of the match, and finally the order in which the rules are specified.
TokensRegex Rules
The TokensRegex rules format is described in SequenceMatchRules. There are two types of rules: assignment rules which can be used to define variables for later use, and extraction rules used in the pipeline for matching expressions.
Extraction rules are specified in a JSON-like language.
Example:
{ // ruleType is "text", "tokens", "composite", or "filter" ruleType: "tokens", // pattern to be matched pattern: ( ( [ { ner:PERSON } ]) /was/ /born/ /on/ ([ { ner:DATE } ]) ), // value associated with the expression for which the pattern was matched // matched expressions are returned with "DATE_OF_BIRTH" as the value // (as part of the MatchedExpression class) result: "DATE_OF_BIRTH" }
See SequenceMatchRules for more details on the fields that can go in an extraction rule definition.
As a short hand, extraction rules that only have the pattern and result fields can be expressed as:
For instance, the above rule can be rewritten as:{ pattern => result }
{ ( ( [ { ner:PERSON } ]) /was/ /born/ /on/ ([ { ner:DATE } ]) ) => "DATE_OF_BIRTH" }
There are four types of extraction rules: text, tokens, composite and filter.
-
The text rules are applied on the raw text and match against regular expressions over strings (the
patternfield should have the form/abc/where abc is a Java regular expression. -
The tokens rules are applied on the tokens and match against regular expressions over tokens (the
patternfield should have the form( abc )where abc is a TokensRegex expression. This type is the default. - The composite rules are applied on previously matched expressions (i.e., those expressions matched by the text, tokens, or previous composite rules), and are repeatedly applied until there are no new matches. These are also specifed as TokensRegex expressions.
- The filter rules are also applied on previously matched expressions. They are applied at the end of each stage and used to filter out expressions (i.e., expressions that match the filter patterns are discarded from the list of matches). These are also specifed as TokensRegex expressions.
Assignment rules are used to define variables for later use.
For example, to bind annotation keys:
tokens = { type: "CLASS", value: "edu.stanford.nlp.ling.CoreAnnotations$TokensAnnotation" }
These variables can be used for matching against those annotation keys, or generating new annotations using those keys.
Assignment rules can also be used to bind TokensRegex patterns.
$DAYOFWEEK = "/monday|tuesday|wednesday|thursday|friday|saturday|sunday/"
$TIMEOFDAY = "/morning|afternoon|evening|night|noon|midnight/"
// Match expressions like "monday afternoon"
{
ruleType: "tokens",
pattern: ( $DAYOFWEEK $TIMEOFDAY ),
result: "TIME"
}
See SequenceMatchRules for other possible uses of assignment rules.
Pattern Language
The TokensRegex pattern language is designed to be similar to standard Java regular expressions. Many of the concepts from standard regular expressions for strings, such as wildcards and capturing groups, are supported by TokensRegex and use a similar syntax. The specifics of the language are described below. The main difference is in the syntax for matching individual tokens.
Defining a regular expression for matching a single token
In Stanford CoreNLP, tokens are represented as a CoreMap (essentially a mapping from an attribute key (Class) to an attribute value (Object)).
TokensRegex supports matching attributes by specifying the key and the value to be matched.
Each token is indicated by [ <expression> ] where <expression> specifies how the attributes should be matched.
Basic expression - Basic expressions are enclosed with {} and have the form { <attr1>; <attr2>...}, where each <attr> specifies a <name> <matchfunc> <value>. See Attribute Match Expression for a summary of the constructs for matching attributes, and Annotation Keys for the attribute names.
- Exact string match
{ word:"..." }[ { word:"cat" } ]matches a token with text equal to "cat" - String regular expression match
{ word:/.../ }[ { word:/cat|dog/ } ]matches a token with text "cat" or "dog" - Multiple attributes match
{ word:...; tag:... }[ { word:/cat|dog/; tag:"NN" } ]matches a token with text "cat" or "dog" and POS tag is NN - Numeric expression match with
==,!=,>=,<=,>,<[ { word>=4 } ]matches a token with text that has numeric value greater than or equal to 4.
As a shorthand, the token text can be matched directly by using "" (for exact string match) or // (for regular expression match).
- You can write
"cat"instead of[ { word:"cat" } ] - You can write
/cat|dog/instead of[ { word:/cat|dog/ } ]
Compound Expressions - Compound expressions are formed using
!, &, and |.
- Use
()to group expressions - Negation:
!{X}
[ !{ tag:/VB.*/ } ]matches any token that is not a verb -
Conjunction:
{X} & {Y}
[ {word>=1000} & {word <=2000} ]matches when the token text is a number between 1000 and 2000 - Disjunction:
{X} | {Y}
[ {word::IS_NUM} | {tag:CD} ]matches when the token text is numeric or is the POS tag is CD
Annotation Keys
Here are standard names for the most commonly used annotation keys. There are many other know annotation keys.
| Name | Annotation Class |
|---|---|
| word | CoreAnnotations.TextAnnotation |
| tag | CoreAnnotations.PartOfSpeechTagAnnotation |
| lemma | CoreAnnotations.LemmaAnnotation |
| ner | CoreAnnotations.NamedEntityTagAnnotation |
| normalized | CoreAnnotations.NormalizedNamedEntityTagAnnotation |
Case Insensitivity
Useenv.setDefaultStringMatchFlags(NodePattern.CASE_INSENSITIVE) and env.setDefaultStringPatternFlags(Pattern.CASE_INSENSITIVE) when using the API, where env is Env env = TokenSequencePattern.getNewEnv() and a pattern is compiled using the env object, for example, TokenSequencePattern p = TokenSequencePattern.compile(env, patternString).
Attribute Match Expressions
| Symbol | Meaning |
|---|---|
| All | |
| [] | Any token |
| Strings | |
| "abc" | The text of the token exactly equals the string abc. |
| /abc/ | The text of the token matches the regular expression specified by abc. This follows the Java regex usage of matches() rather than find(). |
| { key:"abc" } | The token annotation corresponding to key matches the string abc exactly. |
| { key:/abc/ } | The token annotation corresponding to key matches the regular expression specified by abc. |
| Numerics | |
| { key==number } | The token annotation corresponding to key is equal to number. |
| { key!=number } | The token annotation corresponding to key is not equal to number. |
| { key>number } | The token annotation corresponding to key is greater than number. |
| { key<number } | The token annotation corresponding to key is less than number. |
| { key>=number } | The token annotation corresponding to key is greater than or equal to number. |
| { key<=number } | The token annotation corresponding to key is less than or equal to number. |
| Boolean checks | |
| { key::IS_NUM } | The token annotation corresponding to key is a number. |
| { key::IS_NIL } or { key::NOT_EXISTS } | The token annotation corresponding to key does not exist. |
| { key::NOT_NIL } or { key::EXISTS } | The token annotation corresponding to key exist. |
Defining regular expression for matching multiple tokens
Sometimes it is useful to be able to match string sequences across tokens irrespective of the tokenization.
| Symbol | Meaning |
|---|---|
| (?m){n,m} /abc/ | The text of a sequence of tokens (between n to m tokens long) should match the regular expression specified by abc. The tokens are concantenated for every match so avoid using with long sequences. |
Defining regular expressions over token sequences
TokensRegex supports a similar set of constructs for matching sequences of tokens as regular expressions over strings.
| Symbol | Meaning |
|---|---|
| X Y | X followed by Y |
| X | Y | X or Y |
| X & Y | X and Y |
| Groups | |
| (X) | X as a capturing group |
| (?$name X) | X as a capturing group with name name |
| (?: X) | X as a non-capturing group |
| Greedy quantifiers | |
| X? | X, once or not at all |
| X* | X, zero or more times |
| X+ | X, one or more times |
| X{n} | X, exactly n times |
| X{n,} | X, at least n times |
| X{n,m} | X, at least n times but no more than m times |
| Reluctant quantifiers | |
| X?? | X, once or not at all |
| X*? | X, zero or more times |
| X+? | X, one or more times |
| X{n}? | X, exactly n times |
| X{n,}? | X, at least n times |
| X{n,m}? | X, at least n times but no more than m times |
Summary of the different bracketing symbols used in TokenRegex
- Square brackets
[...]are used to indicates one token - Parentheses
(...)are used to indicate grouping (including capturing groups for sequences) - Braces
{...}are used to indicate attributes matching an expression (or the number of times the group should repeat for sequences) - Slashes
/.../are used to indicate regular expression patterns over strings - Quotes
"..."are used to indicate a string
TokensRegex with other (human) languages
All the examples above have been for English, but there is nothing English-specific about TokensRegex. You can also use it to match against token sequences in any other human language. Here are a couple of rules for Chinese:
kbpentity = { type: "CLASS", value: "edu.stanford.nlp.kbp.slotfilling.classify.TokensRegexExtractor$KBPEntity" }
slotvalue = { type: "CLASS", value: "edu.stanford.nlp.kbp.slotfilling.classify.TokensRegexExtractor$KBPSlotFill" }
$ENTITY = ([ { kbpentity:true } ]+ )
$AGE = ( [ { slotvalue::EXISTS } & { word:/[0-9]{1,2}/ } ] )
{ result: "per:age", pattern: ( $AGE /岁/ /的/ $ENTITY ) }
{ result: "per:age", pattern: ( $ENTITY []{0, 10} /享年|终年|圆寂|世寿/ $AGE /岁/) }
Download
TokensRegex is integrated in the Stanford suite of NLP tools, StanfordCoreNLP. Please download the entire suite from this page.
Questions
Questions, feedback, and bug reports/fixes can be sent to our mailing lists.
Mailing Lists
We have 3 mailing lists for TokensRegex, all of which are shared
with other JavaNLP tools (with the exclusion of the parser). Each address is
at @lists.stanford.edu:
java-nlp-userThis is the best list to post to in order to ask questions, make announcements, or for discussion among JavaNLP users. You have to subscribe to be able to use it. Join the list via this webpage or by emailingjava-nlp-user-join@lists.stanford.edu. (Leave the subject and message body empty.) You can also look at the list archives.java-nlp-announceThis list will be used only to announce new versions of Stanford JavaNLP tools. So it will be very low volume (expect 1-3 messages a year). Join the list via this webpage or by emailingjava-nlp-announce-join@lists.stanford.edu. (Leave the subject and message body empty.)java-nlp-supportThis list goes only to the software maintainers. It's a good address for licensing questions, etc. For general use and support questions, you're better off joining and usingjava-nlp-user. You cannot joinjava-nlp-support, but you can mail questions tojava-nlp-support@lists.stanford.edu.
Release History
| 2013 on | Subsequent enhancements to TokensRegex appear in releases of StanfordCoreNLP | |
| Version 1.3.2 | 2012-05-22 | Added TokensRegexAnnotator that can be configured using a rules file |
| Version 1.2.0 | 2011-09-14 | Initial version of TokensRegex library |