<scene ...> and
</scene>. It
has an attribute
number with value vii and two child elements,
title and verse.
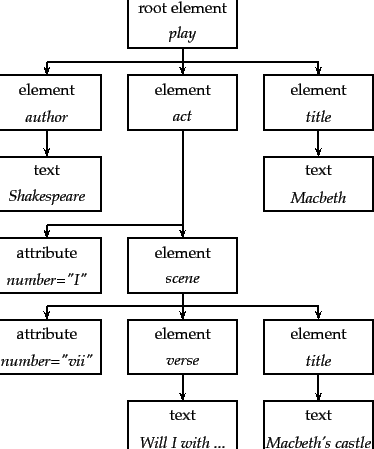
Figure 10.2 shows Figure 10.1 as a tree. The leaf nodes of the tree consist of text, e.g., Shakespeare, Macbeth, and Macbeth's castle. The tree's internal nodes encode either the structure of the document (title, act, and scene) or metadata functions (author).
The standard for accessing and processing XML
documents is the XML Document Object Model or DOM . The DOM represents elements, attributes and text within
elements as
nodes in a tree. Figure 10.2 is a simplified DOM representation of
the XML document in Figure 10.1 .![]() With a DOM API, we can process an
XML document by starting at the root element and then
descending down the tree from parents to children.
With a DOM API, we can process an
XML document by starting at the root element and then
descending down the tree from parents to children.
XPath is a standard for enumerating paths in an XML
document collection.
We will also refer to paths as
XML contexts
or simply contexts
in
this chapter. Only a small subset of XPath is needed for our purposes.
The
XPath expression node selects all nodes of that name.
Successive elements of a path are separated by slashes, so
act/scene selects all scene elements whose
parent is an act element.
Double slashes indicate that an arbitrary number of elements
can intervene on a path:
play//scene selects all scene elements
occurring in a play element. In Figure 10.2
this set consists of a single scene element, which is accessible via
the path
play,
act,
scene from the top. An initial slash starts the path
at the root element.
/play/title selects the play's title in
Figure 10.1 ,
/play//title selects a set with two members (the play's title and the scene's
title), and
/scene/title selects no elements. For notational convenience, we
allow the final element of a path to be a vocabulary term and
separate it from the element path by the symbol #, even
though this does not conform to the XPath standard. For example, title#"Macbeth"
selects all titles containing the term Macbeth.
We also need the concept of schema in this chapter. A schema puts constraints on the structure of allowable XML documents for a particular application. A schema for Shakespeare's plays may stipulate that scenes can only occur as children of acts and that only acts and scenes have the number attribute. Two standards for schemas for XML documents are XML DTD (document type definition) and XML Schema . Users can only write structured queries for an XML retrieval system if they have some minimal knowledge about the schema of the collection.
A common format for XML queries is
NEXI (Narrowed Extended XPath I). We give an example
in Figure 10.3 .
We display the query on four lines for typographical
convenience, but it is intended to be read as one unit
without line breaks. In
particular, //section is embedded under //article.
The query
in Figure 10.3
specifies a search for
sections about the
summer holidays that are part of
articles from 2001 or 2002.
As in XPath
double slashes indicate that an arbitrary number of elements
can intervene on a path.
The dot in a clause in square brackets refers to the element
the clause modifies.
The clause [.//yr = 2001 or .//yr = 2002] modifies //article.
Thus,
the dot refers to
//article in this case.
Similarly, the dot in
[about(., summer holidays)]
refers to the section that the clause modifies.
The two yr conditions are
relational attribute constraints. Only articles whose yr
attribute is 2001 or 2002 (or that contain an element whose
yr attribute is 2001 or 2002) are to be considered.
The about clause is a ranking constraint: Sections
that occur in the right type of article
are to be ranked according
to how relevant they are to the topic summer
holidays.
We usually handle relational attribute constraints by prefiltering or postfiltering: We simply exclude all elements from the result set that do not meet the relational attribute constraints. In this chapter, we will not address how to do this efficiently and instead focus on the core information retrieval problem in XML retrieval, namely how to rank documents according to the relevance criteria expressed in the about conditions of the NEXI query.
If we discard relational attributes, we can represent documents
as trees with only one type of node: element nodes. In other
words, we remove all attribute nodes from the XML document,
such as the number attribute in
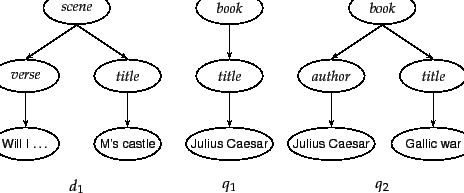
Figure 10.1 . Figure 10.4 shows a subtree of
the document in Figure 10.1 as an element-node tree
(labeled ![]() ).
).
We can represent queries as trees in the same way. This is a
query-by-example approach to query language
design because users pose queries by creating objects that
satisfy the same formal description as documents. In Figure 10.4 ,
![]() is a search
for books whose titles score highly for the keywords Julius Caesar.
is a search
for books whose titles score highly for the keywords Julius Caesar. ![]() is a
search for books whose author elements score highly for
Julius Caesar and whose title elements score highly
for Gallic war.
is a
search for books whose author elements score highly for
Julius Caesar and whose title elements score highly
for Gallic war.![]()