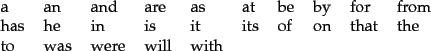Sometimes, some extremely common words which would appear to be of little value in helping select documents matching a user need are excluded from the vocabulary entirely. These words are called stop words . The general strategy for determining a stop list is to sort the terms by collection frequency (the total number of times each term appears in the document collection), and then to take the most frequent terms, often hand-filtered for their semantic content relative to the domain of the documents being indexed, as a stop list , the members of which are then discarded during indexing. An example of a stop list is shown in Figure 2.5 . Using a stop list significantly reduces the number of postings that a system has to store; we will present some statistics on this in Chapter 5 (see Table 5.1 , page 5.1 ). And a lot of the time not indexing stop words does little harm: keyword searches with terms like the and by don't seem very useful. However, this is not true for phrase searches. The phrase query ``President of the United States'', which contains two stop words, is more precise than President AND ``United States''. The meaning of flights to London is likely to be lost if the word to is stopped out. A search for Vannevar Bush's article As we may think will be difficult if the first three words are stopped out, and the system searches simply for documents containing the word think. Some special query types are disproportionately affected. Some song titles and well known pieces of verse consist entirely of words that are commonly on stop lists (To be or not to be, Let It Be, I don't want to be, ...).
The general trend in IR systems over time has been from standard use of
quite large stop
lists (200-300 terms) to very small stop lists (7-12 terms) to no stop
list whatsoever. Web search engines generally do not use stop lists. Some
of the design of modern IR systems has focused precisely on how we can
exploit the statistics of language so as to be able to cope with common
words in better ways. We will show in Section 5.3 (page ![]() ) how good
compression techniques greatly reduce the cost of storing the postings
for common words. idf then discusses how standard term weighting
leads to very common words having little impact on document rankings. Finally,
Section 7.1.5 (page
) how good
compression techniques greatly reduce the cost of storing the postings
for common words. idf then discusses how standard term weighting
leads to very common words having little impact on document rankings. Finally,
Section 7.1.5 (page ![]() ) shows how an IR
system with impact-sorted indexes can terminate scanning a postings list
early when weights get small, and hence common words do not cause a large
additional processing cost for the average query, even though postings lists
for stop
words are very long. So for most modern IR systems, the additional cost
of including stop words is not that big - neither in terms of index
size nor in terms of query processing time.
) shows how an IR
system with impact-sorted indexes can terminate scanning a postings list
early when weights get small, and hence common words do not cause a large
additional processing cost for the average query, even though postings lists
for stop
words are very long. So for most modern IR systems, the additional cost
of including stop words is not that big - neither in terms of index
size nor in terms of query processing time.