




Next: Probabilistic information retrieval
Up: XML retrieval
Previous: References and further reading
Contents
Index
Exercises.
- Find a reasonably sized
XML document collection (or a collection using a markup
language different from XML like HTML) on the web and download
it.
Jon Bosak's XML edition of Shakespeare and of various
religious works at
http://www.ibiblio.org/bosak/
or
the first 10,000 documents of the Wikipedia are good
choices. Create three CAS topics of the type shown in
Figure 10.3 that you would expect to do better than
analogous CO topics. Explain why an XML retrieval
system would be able to exploit the XML structure of the
documents to achieve better
retrieval results on the topics than an unstructured retrieval system.
- For the collection and the
topics in Exercise 10.7 , (i) are there pairs of
elements
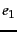 and
and 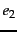 , with a subelement of such that both answer one of the
topics?
Find one case each where (ii) (iii) is the better
answer to the query.
, with a subelement of such that both answer one of the
topics?
Find one case each where (ii) (iii) is the better
answer to the query.
- Implement the (i) SIMMERGE (ii) SIMNOMERGE algorithm in
Section 10.3 and run it for the collection and the
topics in Exercise 10.7 . (iii) Evaluate the results
by assigning binary relevance judgments to the first five
documents of the three retrieved lists for each algorithm. Which algorithm
performs better?
- Are all of the elements in Exercise 10.7
appropriate to be returned as hits to a user or are there
elements (as in the example
<b>definitely</b> on page 10.2 ) that you would exclude?
-
We discussed the tradeoff between accuracy of results and
dimensionality of the vector space on page 10.3 .
Give an example of an information need that we can answer correctly if we
index all lexicalized subtrees, but cannot answer if we only
index structural terms.
- If we index all structural terms,
what is the size of the index as a function of text size?
- If we index all lexicalized subtrees,
what is the size of the index as a function of text size?
- Give an example of a query-document pair for which
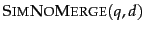 is larger than 1.0.
is larger than 1.0.
Next: Probabilistic information retrieval
Up: XML retrieval
Previous: References and further reading
Contents
Index
© 2008 Cambridge University Press
This is an automatically generated page. In case of formatting errors you may want to look at the PDF edition of the book.
2009-04-07