




Next: Comparison of feature selection
Up: Feature selection
Previous: Frequency-based feature selection
Contents
Index
Feature selection for multiple classifiers
In an operational system with a large number of classifiers,
it is desirable to select a single set of features instead
of a different one for each classifier. One way of doing
this is to compute the 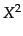 statistic for an
statistic for an 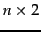 table where the columns are occurrence and nonoccurrence of
the term and each row corresponds to one of the classes. We
can then select the
table where the columns are occurrence and nonoccurrence of
the term and each row corresponds to one of the classes. We
can then select the 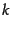 terms with the highest
statistic as before.
terms with the highest
statistic as before.
More commonly, feature selection statistics are first
computed separately for each class on the two-class
classification task 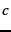 versus
versus 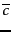 and then
combined. One combination method computes
a single figure of
merit for each feature, for example, by averaging the values
and then
combined. One combination method computes
a single figure of
merit for each feature, for example, by averaging the values
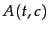 for feature
for feature 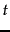 , and then selects the
features with highest figures of merit. Another frequently used combination method selects
the top
, and then selects the
features with highest figures of merit. Another frequently used combination method selects
the top 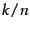 features for each of
features for each of 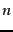 classifiers and
then combines these sets into one global feature set.
classifiers and
then combines these sets into one global feature set.
Classification accuracy often decreases when
selecting common features for a system with
classifiers as opposed to different sets of size
. But even if it does, the gain in efficiency owing to
a common document representation may be worth the loss in
accuracy .
Next: Comparison of feature selection
Up: Feature selection
Previous: Frequency-based feature selection
Contents
Index
© 2008 Cambridge University Press
This is an automatically generated page. In case of formatting errors you may want to look at the PDF edition of the book.
2009-04-07