The second consideration is politeness: we must avoid repeated fetch requests to a host within a short time span. The likelihood of this is exacerbated because of a form of locality of reference: many URLs link to other URLs at the same host. As a result, a URL frontier implemented as a simple priority queue might result in a burst of fetch requests to a host. This might occur even if we were to constrain the crawler so that at most one thread could fetch from any single host at any time. A common heuristic is to insert a gap between successive fetch requests to a host that is an order of magnitude larger than the time taken for the most recent fetch from that host.
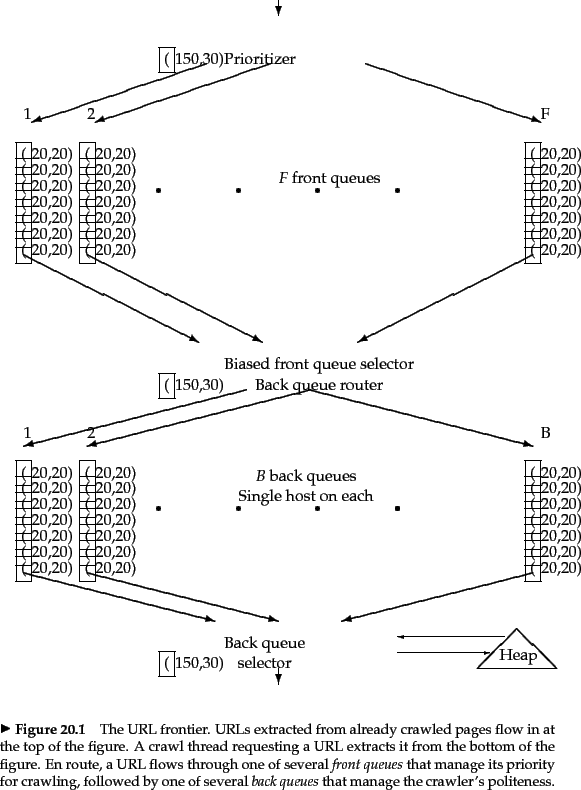
Figure 20.3 shows a polite and prioritizing implementation of a URL frontier. Its goals are to ensure that (i) only one connection is open at a time to any host; (ii) a waiting time of a few seconds occurs between successive requests to a host and (iii) high-priority pages are crawled preferentially.
The two major sub-modules are a set of ![]() front queues in the upper portion of the figure,
and a set of
front queues in the upper portion of the figure,
and a set of ![]() back queues in the lower part; all of these are FIFO queues. The front queues implement the prioritization, while the back queues implement politeness. In the flow of a URL added to the frontier as it makes its way through the front and back queues, a prioritizer first assigns to the URL an integer priority
back queues in the lower part; all of these are FIFO queues. The front queues implement the prioritization, while the back queues implement politeness. In the flow of a URL added to the frontier as it makes its way through the front and back queues, a prioritizer first assigns to the URL an integer priority ![]() between 1 and
between 1 and ![]() based on its fetch history (taking into account the rate at which the web page at this URL has changed between previous crawls). For instance, a document that has exhibited frequent change would be assigned a higher priority. Other heuristics could be application-dependent and explicit - for instance, URLs from news services may always be assigned the highest priority. Now that it has been assigned priority
based on its fetch history (taking into account the rate at which the web page at this URL has changed between previous crawls). For instance, a document that has exhibited frequent change would be assigned a higher priority. Other heuristics could be application-dependent and explicit - for instance, URLs from news services may always be assigned the highest priority. Now that it has been assigned priority ![]() , the URL is now appended to the
, the URL is now appended to the ![]() th of the front queues.
th of the front queues.
Each of the ![]() back queues maintains the following invariants: (i) it is non-empty while the crawl is in progress and (ii) it only contains URLs from a single host
back queues maintains the following invariants: (i) it is non-empty while the crawl is in progress and (ii) it only contains URLs from a single host![]() . An auxiliary table
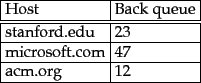
. An auxiliary table ![]() (Figure 20.4 ) is used to maintain the mapping from hosts to back queues. Whenever a back-queue is empty and is being re-filled from a front-queue, table
(Figure 20.4 ) is used to maintain the mapping from hosts to back queues. Whenever a back-queue is empty and is being re-filled from a front-queue, table ![]() must be updated accordingly.
must be updated accordingly.
In addition, we maintain a heap with one entry for each back queue, the entry being the earliest time ![]() at which the host corresponding to that queue can be contacted again.
at which the host corresponding to that queue can be contacted again.
A crawler thread requesting a URL from the frontier extracts the
root of this heap and (if necessary) waits until the corresponding
time entry ![]() . It then takes the URL
. It then takes the URL ![]() at the head of the back
queue
at the head of the back
queue ![]() corresponding to the extracted heap root, and proceeds to
fetch the URL
corresponding to the extracted heap root, and proceeds to
fetch the URL ![]() . After fetching
. After fetching ![]() , the calling thread checks
whether
, the calling thread checks
whether ![]() is empty. If so, it picks a front queue and extracts
from its head a URL
is empty. If so, it picks a front queue and extracts
from its head a URL ![]() . The choice of front queue is biased (usually by a random process) towards queues of higher priority, ensuring that URLs of high priority flow more quickly into the back queues. We examine
. The choice of front queue is biased (usually by a random process) towards queues of higher priority, ensuring that URLs of high priority flow more quickly into the back queues. We examine ![]() to check whether there is already a back queue holding URLs from its host. If so,
to check whether there is already a back queue holding URLs from its host. If so, ![]() is added to that queue and we reach back to the front queues to find another candidate URL for insertion into the now-empty queue
is added to that queue and we reach back to the front queues to find another candidate URL for insertion into the now-empty queue ![]() . This process continues until
. This process continues until ![]() is non-empty again. In any case, the thread inserts a heap entry for
is non-empty again. In any case, the thread inserts a heap entry for ![]() with a new earliest time
with a new earliest time ![]() based on the properties of the URL in
based on the properties of the URL in ![]() that was last fetched (such as when its host was last contacted as well as the time taken for the last fetch), then continues with its processing. For instance, the new entry
that was last fetched (such as when its host was last contacted as well as the time taken for the last fetch), then continues with its processing. For instance, the new entry ![]() could be the current time plus ten times the last fetch time.
could be the current time plus ten times the last fetch time.
The number of front queues, together with the policy of assigning priorities and picking queues, determines the priority properties we wish to build into the system. The number of back queues governs the extent to which we can keep all crawl threads busy while respecting politeness. The designers of Mercator recommend a rough rule of three times as many back queues as crawler threads.
On a Web-scale crawl, the URL frontier may grow to the point where it demands more memory at a node than is available. The solution is to let most of the URL frontier reside on disk. A portion of each queue is kept in memory, with more brought in from disk as it is drained in memory.
Exercises.