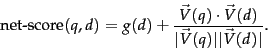The net score for a document ![]() is some combination of
is some combination of ![]() together with the query-dependent score induced (say) by (27). The precise combination may be determined by the learning methods of Section 6.1.2 , to be developed further in Section 15.4.1 ; but for the purposes of our exposition here, let us consider a simple sum:
together with the query-dependent score induced (say) by (27). The precise combination may be determined by the learning methods of Section 6.1.2 , to be developed further in Section 15.4.1 ; but for the purposes of our exposition here, let us consider a simple sum:
First, consider ordering the documents in the postings list for each term by decreasing value of ![]() . This allows us to perform the postings intersection algorithm of Figure 1.6 . In order to perform the intersection by a single pass through the postings of each query term, the algorithm of Figure 1.6 relied on the postings being ordered by document IDs. But in fact, we only required that all postings be ordered by a single common ordering; here we rely on the
. This allows us to perform the postings intersection algorithm of Figure 1.6 . In order to perform the intersection by a single pass through the postings of each query term, the algorithm of Figure 1.6 relied on the postings being ordered by document IDs. But in fact, we only required that all postings be ordered by a single common ordering; here we rely on the ![]() values to provide this common ordering. This is illustrated in Figure 7.2 , where the postings are ordered in decreasing order of
values to provide this common ordering. This is illustrated in Figure 7.2 , where the postings are ordered in decreasing order of ![]() .
.
![\includegraphics[width=13cm]{gd.eps}](img495.png) A static quality-ordered index.In this example we assume that Doc1, Doc2 and Doc3 respectively have static quality scores
A static quality-ordered index.In this example we assume that Doc1, Doc2 and Doc3 respectively have static quality scores
The first idea is a direct extension of champion lists: for a well-chosen value ![]() , we maintain for each term
, we maintain for each term ![]() a global champion list of the
a global champion list of the ![]() documents with the highest values for
documents with the highest values for
![]() . The list itself is, like all the postings lists considered so far, sorted by a common order (either by document IDs or by static quality). Then at query time, we only compute the net scores (35) for documents in the union of these global champion lists. Intuitively, this has the effect of focusing on documents likely to have large net scores.
. The list itself is, like all the postings lists considered so far, sorted by a common order (either by document IDs or by static quality). Then at query time, we only compute the net scores (35) for documents in the union of these global champion lists. Intuitively, this has the effect of focusing on documents likely to have large net scores.
We conclude the discussion of global champion lists with one further idea. We maintain for each term ![]() two postings lists consisting of disjoint sets of documents, each sorted by
two postings lists consisting of disjoint sets of documents, each sorted by ![]() values. The first list, which we call high, contains the
values. The first list, which we call high, contains the ![]() documents with the highest tf values for
documents with the highest tf values for ![]() . The second list, which we call low, contains all other documents containing
. The second list, which we call low, contains all other documents containing ![]() . When processing a query, we first scan only the high lists of the query terms, computing net scores for any document on the high lists of all (or more than a certain number of) query terms. If we obtain scores for
. When processing a query, we first scan only the high lists of the query terms, computing net scores for any document on the high lists of all (or more than a certain number of) query terms. If we obtain scores for ![]() documents in the process, we terminate. If not, we continue the scanning into the low lists, scoring documents in these postings lists. This idea is developed further in Section 7.2.1 .
documents in the process, we terminate. If not, we continue the scanning into the low lists, scoring documents in these postings lists. This idea is developed further in Section 7.2.1 .