There are two different ways we can set up an NB classifier. The model we introduced in the previous section is the multinomial model . It generates one term from the vocabulary in each position of the document, where we assume a generative model that will be discussed in more detail in Section 13.4 (see also page 12.1.1 ).
An alternative to the multinomial model
is the
multivariate Bernoulli model
or
Bernoulli model . It is equivalent to the
binary independence model
of Section 11.3 (page ![]() ), which generates an
indicator for each term of the vocabulary, either
), which generates an
indicator for each term of the vocabulary, either
![]() indicating presence of the term in
the document
or
indicating presence of the term in
the document
or ![]() indicating absence. Figure 13.3 presents training and
testing algorithms for the Bernoulli model. The Bernoulli model
has the same time complexity as the multinomial model.
indicating absence. Figure 13.3 presents training and
testing algorithms for the Bernoulli model. The Bernoulli model
has the same time complexity as the multinomial model.
The different generation models imply different estimation
strategies and different classification rules. The Bernoulli model estimates
![]() as the fraction of documents of
class
as the fraction of documents of
class ![]() that contain term
that contain term ![]() (Figure 13.3 ,
TRAINBERNOULLINB, line 8). In contrast, the
multinomial model estimates
(Figure 13.3 ,
TRAINBERNOULLINB, line 8). In contrast, the
multinomial model estimates
![]() as the
fraction of tokens or fraction of positions in
documents of class
as the
fraction of tokens or fraction of positions in
documents of class ![]() that contain term
that contain term ![]() (Equation 119).
When classifying a test document, the
Bernoulli model uses binary occurrence information, ignoring
the number of occurrences, whereas the multinomial model
keeps track of multiple occurrences. As a result, the
Bernoulli model typically makes many mistakes when
classifying long documents. For example, it may assign an
entire book to the class China because of a single
occurrence of the term China.
(Equation 119).
When classifying a test document, the
Bernoulli model uses binary occurrence information, ignoring
the number of occurrences, whereas the multinomial model
keeps track of multiple occurrences. As a result, the
Bernoulli model typically makes many mistakes when
classifying long documents. For example, it may assign an
entire book to the class China because of a single
occurrence of the term China.
The models also differ in how nonoccurring terms are used
in classification. They do not affect the classification
decision in the multinomial model; but in the Bernoulli model
the probability of nonoccurrence is factored in when
computing ![]() (Figure 13.3 , APPLYBERNOULLINB, Line 7). This is because only the
Bernoulli NB model models absence of terms explicitly.
(Figure 13.3 , APPLYBERNOULLINB, Line 7). This is because only the
Bernoulli NB model models absence of terms explicitly.
Worked example. Applying the Bernoulli model to
the example in Table 13.1 , we have the same estimates
for the priors as before:
![]() ,
,
![]() . The conditional probabilities are:
. The conditional probabilities are:
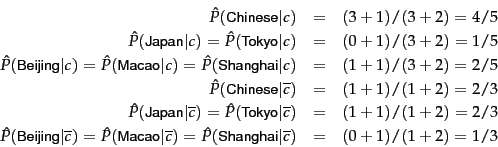
The denominators are ![]() and
and ![]() because
there are three documents in
because
there are three documents in ![]() and one document in
and one document in ![]() and because
the constant
and because
the constant ![]() in
Equation 119 is 2 - there are two cases to consider for
each term, occurrence and nonoccurrence.
in
Equation 119 is 2 - there are two cases to consider for
each term, occurrence and nonoccurrence.
The scores of the test document for the two classes are

