Training¶
Training “Hello World”¶
You should now be ready to launch a demo training run. There are example
configurations for training on WikiText-2 in conf/mistral-micro.yaml. You
will need to update the artifacts directories and the wandb settings in this file before
running training.
To launch a training run, use this command:
cd mistral
conda activate mistral
CUDA_VISIBLE_DEVICES=0 python train.py --config conf/mistral-micro.yaml --nnodes 1 --nproc_per_node 1 --training_arguments.fp16 true --training_arguments.per_device_train_batch_size 2
You may need to adjust your batch size depending on the available GPU memory.
Example Output¶
If all is successful, you should see output similar to this:
|=>> 06/25 [23:58:36] - mistral - INFO :: Initializing Model Trainer...
|=>> 06/25 [23:58:36] - mistral - INFO :: Training Arguments: TrainingArguments(output_dir=mistral-hello-world/runs/gpt2-small-d=wikitext-n=1-g=1-w=1+2021-06-25-23:57:32, overwrite_output_dir=False, do_train=True, do_eval=None, do_predict=False, evaluation_strategy=IntervalStrategy.STEPS, prediction_loss_only=True, per_device_train_batch_size=4, per_device_eval_batch_size=16, gradient_accumulation_steps=128, eval_accumulation_steps=None, learning_rate=0.0006, weight_decay=0.1, adam_beta1=0.9, adam_beta2=0.95, adam_epsilon=1e-08, max_grad_norm=1.0, num_train_epochs=3.0, max_steps=400000, lr_scheduler_type=SchedulerType.LINEAR, warmup_ratio=0.0, warmup_steps=4000, logging_dir=logs, logging_strategy=IntervalStrategy.STEPS, logging_first_step=True, logging_steps=50, save_strategy=IntervalStrategy.STEPS, save_steps=1000, save_total_limit=None, no_cuda=False, seed=21, fp16=True, fp16_opt_level=O1, fp16_backend=auto, fp16_full_eval=False, local_rank=-1, tpu_num_cores=None, tpu_metrics_debug=False, debug=False, dataloader_drop_last=False, eval_steps=1000, dataloader_num_workers=4, past_index=-1, run_name=gpt2-small-d=wikitext-n=1-g=1-w=1+2021-06-25-23:57:32, disable_tqdm=False, remove_unused_columns=True, label_names=None, load_best_model_at_end=False, metric_for_best_model=None, greater_is_better=None, ignore_data_skip=False, sharded_ddp=[], deepspeed=None, label_smoothing_factor=0.0, adafactor=False, group_by_length=False, length_column_name=length, report_to=[], ddp_find_unused_parameters=None, dataloader_pin_memory=True, skip_memory_metrics=False, _n_gpu=1, mp_parameters=)
|=>> 06/25 [23:58:42] - mistral.core.callbacks - INFO :: Setting W&B Project: hello-world
|=>> 06/25 [23:59:06] - mistral - INFO :: Training...
|=>> 06/25 [23:59:06] - mistral.core.callbacks - INFO :: Automatic Weights & Biases logging enabled, to disable set os.environ["WANDB_DISABLED"] = "true"
wandb: Currently logged in as: username (use `wandb login --relogin` to force relogin)
wandb: wandb version 0.10.32 is available! To upgrade, please run:
wandb: $ pip install wandb --upgrade
wandb: Tracking run with wandb version 0.10.21
wandb: Syncing run gpt2-small-d=wikitext-n=1-g=1-w=1+2021-06-25-23:57:32
wandb: ⭐️ View project at https://wandb.ai/smy-team/hello-world
wandb: 🚀 View run at https://wandb.ai/my-team/hello-world/runs/3mrlgblq
wandb: Run data is saved locally in mistral-hello-world/runs/gpt2-small-d=wikitext-n=1-g=1-w=1+2021-06-25-23:57:32/wandb/run-20210625_235915-3mrlgblq
wandb: Run `wandb offline` to turn off syncing.
{'loss': 11.0023, 'learning_rate': 1.5e-07, 'activations/layer0_attention_weight_max': 1.9394148588180542, 'activations/layer0_attention_weight_min': -1.7338905334472656, 'activations/layer1_attention_weight_max': 1.7617545127868652, 'activations/layer1_attention_weight_min': -1.7682685852050781, 'activations/layer2_attention_weight_max': 1.7848472595214844, 'activations/layer2_attention_weight_min': -1.9004961252212524, 'activations/layer3_attention_weight_max': 1.8493074178695679, 'activations/layer3_attention_weight_min': -1.838200330734253, 'activations/layer4_attention_weight_max': 1.8895012140274048, 'activations/layer4_attention_weight_min': -1.7738912105560303, 'activations/layer5_attention_weight_max': 1.7461622953414917, 'activations/layer5_attention_weight_min': -1.758669376373291, 'activations/layer6_attention_weight_max': 1.9132049083709717, 'activations/layer6_attention_weight_min': -1.9518122673034668, 'activations/layer7_attention_weight_max': 1.8657881021499634, 'activations/layer7_attention_weight_min': -1.8033781051635742, 'activations/layer8_attention_weight_max': 2.0741305351257324, 'activations/layer8_attention_weight_min': -1.925511360168457, 'activations/layer9_attention_weight_max': 1.8003664016723633, 'activations/layer9_attention_weight_min': -1.7981972694396973, 'activations/layer10_attention_weight_max': 1.7417181730270386, 'activations/layer10_attention_weight_min': -1.6902594566345215, 'activations/layer11_attention_weight_max': 1.9806346893310547, 'activations/layer11_attention_weight_min': -1.731971025466919, 'epoch': 0.0}
0%| | 100/400000 [1:06:43<4789:29:34, 43.12s/it]
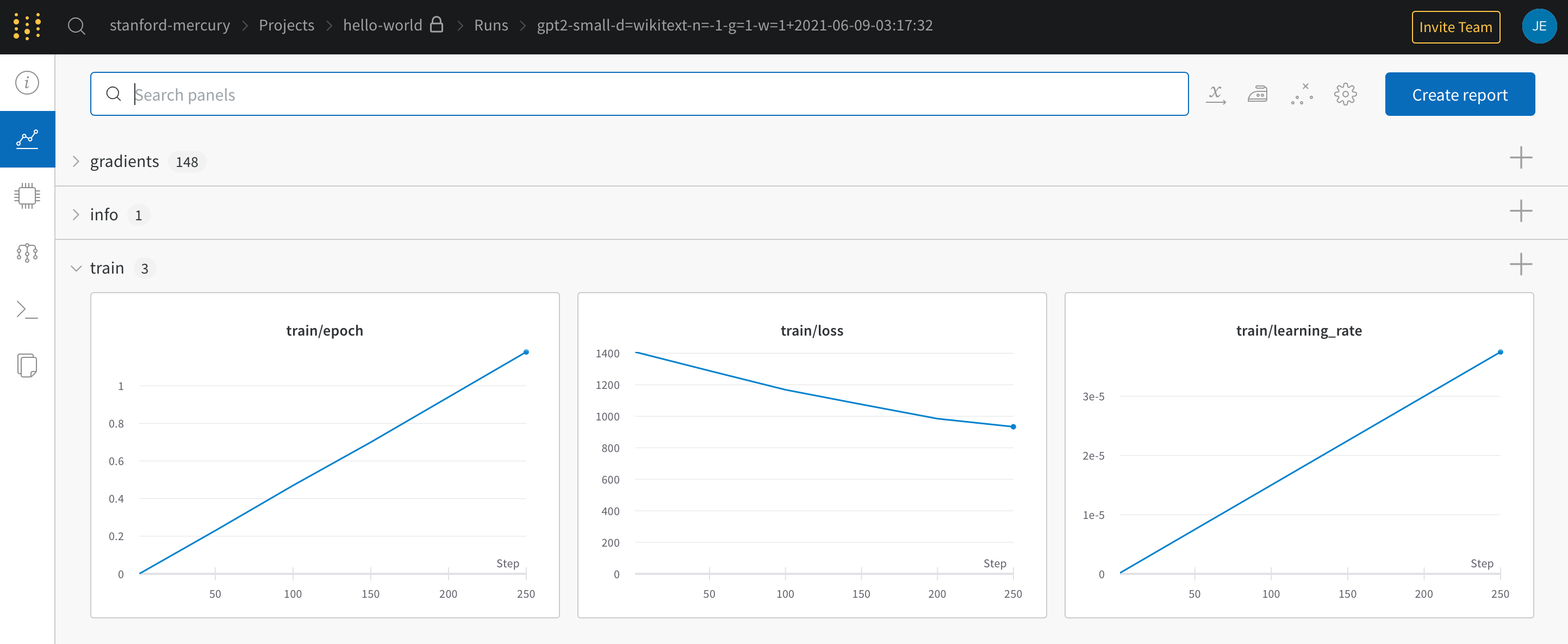
If you sign in to Weights & Biases you should see a variety of logs for your training run, including an active graph of the training loss.